Suy luận phi máy chủ (Serverless Inference) hiện đang là một trong những chủ đề được quan tâm hàng đầu trong cộng đồng người dùng AI, từ các chuyên gia kỹ thuật đến những người không chuyên, và điều này hoàn toàn có lý. Mặc dù việc kiểm soát mọi khía cạnh của quá trình triển khai thường là cần thiết khi vận hành các mô hình tùy chỉnh, nhưng công nghệ phi máy chủ đã loại bỏ gánh nặng trong việc duy trì và quản lý việc triển khai mô hình cũng như các điểm cuối API. Điều này mang lại lợi ích vô cùng to lớn cho vô vàn các trường hợp ứng dụng LLM (Large Language Model) theo hướng tác tử.
Bài viết này sẽ trình bày chi tiết cách bắt đầu với Serverless Inference trên DigitalOcean GradientAI Platform bằng cách sử dụng API của DigitalOcean. Hãy cùng khám phá ngay thôi nào!
Truy Cập Serverless Inference trên DigitalOcean GradientAI Platform
Để bắt đầu, bạn có thể lựa chọn sử dụng DigitalOcean API hoặc Giao diện điều khiển đám mây (Cloud Console). Hãy cùng tìm hiểu chi tiết từng phương pháp.
Bước 1a: Tạo Khóa API DigitalOcean
Trước tiên, bạn cần tạo tài khoản DigitalOcean và đăng nhập. Sau khi hoàn tất, hãy điều hướng đến không gian nhóm mà bạn muốn sử dụng. Tại đây, chúng ta sẽ tạo một khóa API DigitalOcean. Khóa này sẽ hỗ trợ bạn trong việc tạo mã thông báo truy cập mô hình sau này; do đó, bạn có thể bỏ qua bước này và chuyển thẳng đến mục “Bước 2b: Tạo khóa truy cập mô hình bằng Giao diện điều khiển đám mây” nếu muốn.
Sử dụng thanh điều hướng ở bên trái trang chủ và cuộn xuống cho đến khi bạn thấy mục “API”. Nhấp vào để mở trang chủ API. Sau đó, bạn có thể sử dụng nút ở phía trên bên phải để tạo khóa mới.
Trong trang tạo khóa, hãy đặt tên cho khóa của bạn theo ý muốn và cấp các quyền phù hợp. Để thực hiện điều này, bạn có thể cấp quyền đầy đủ hoặc cuộn xuống mục “genai” trong phần lựa chọn phạm vi tùy chỉnh và chọn tất cả. Cuối cùng, hãy tạo khóa và lưu giữ giá trị này để sử dụng sau.
Bước 2A: Tạo Khóa Truy Cập Mô Hình bằng API
Tiếp theo, chúng ta sẽ tạo khóa truy cập mô hình để sử dụng Serverless Inference của GradientAI. Để thực hiện điều này, bạn có thể lựa chọn sử dụng giao diện điều khiển (console) hoặc API. Nếu muốn dùng API, hãy sử dụng khóa API đã lưu trước đó cùng với lệnh curl sau đây trong terminal của bạn. Đừng quên thay thế giá trị “$DIGITALOCEAN_TOKEN” bằng khóa của riêng bạn.

Thao tác này sẽ xuất ra khóa truy cập mô hình của bạn. Hãy lưu lại giá trị này để sử dụng sau, chúng ta sẽ cần đến nó để truy vấn mô hình.
Bước 2B: Tạo khóa truy cập mô hình qua Cloud Console
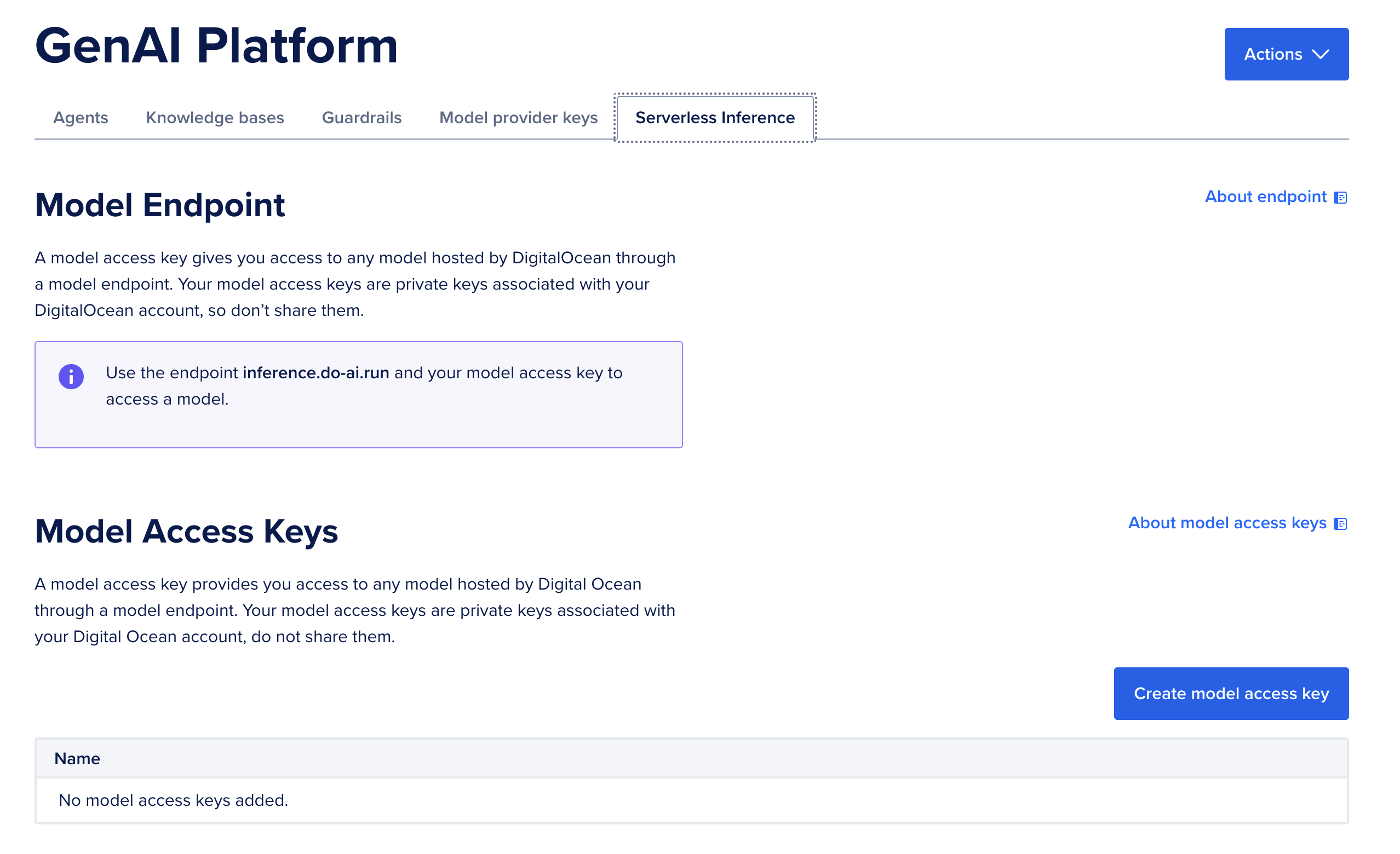
Nếu muốn dùng Console, bạn chỉ cần điều hướng đến thẻ Serverless Inference trong DigitalOcean GradientAI Platform trên Console. Tại đó, hãy nhấp vào nút Tạo khóa truy cập mô hình ở phía dưới bên phải.
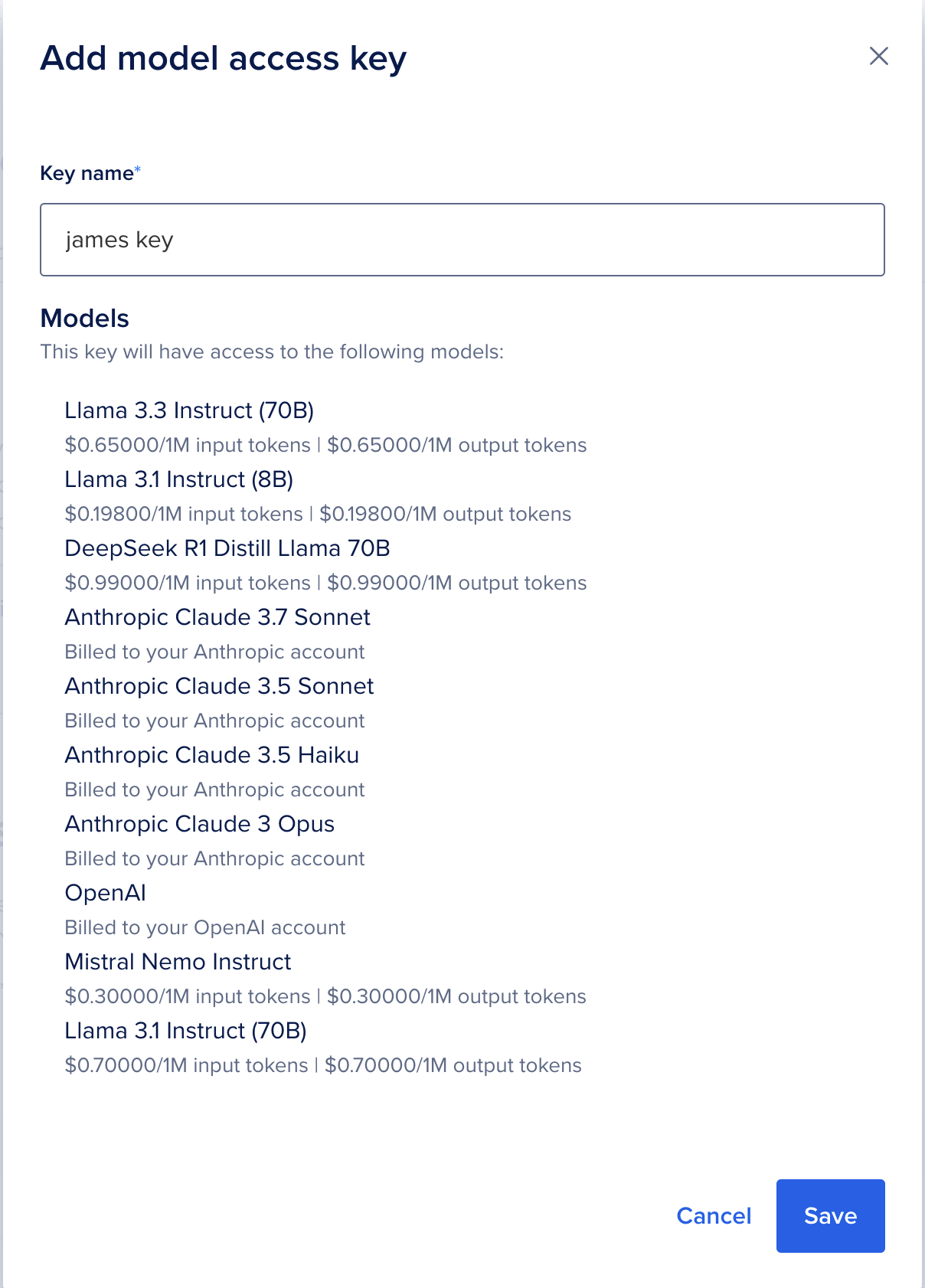
Sau đó, tất cả những gì chúng ta cần làm là đặt tên cho khóa của mình. Hãy nhớ lưu lại giá trị đầu ra này để dùng sau nhé! Bạn sẽ cần đến nó để thực hiện Serverless Inference với Python.
Bước 3: Tạo Văn Bản Với Python và Serverless Inference
Với khóa truy cập mô hình mới, bạn có thể bắt đầu chạy DigitalOcean Serverless Inference từ bất kỳ máy nào có kết nối internet! Chúng tôi khuyên bạn nên làm việc trong Jupyter Notebook. Để biết các mẹo thiết lập môi trường cho bài viết này, hãy làm theo hướng dẫn đã được đề cập.
Sau khi môi trường của bạn đã sẵn sàng, hãy mở một tệp IPython Notebook mới (.ipynb). Sử dụng đoạn mã dưới đây để bắt đầu tạo văn bản, cụ thể là trả lời câu hỏi về thủ đô của Pháp. Đừng quên chỉnh sửa đoạn mã ở dòng 5 để cập nhật giá trị khóa API của bạn nhé.
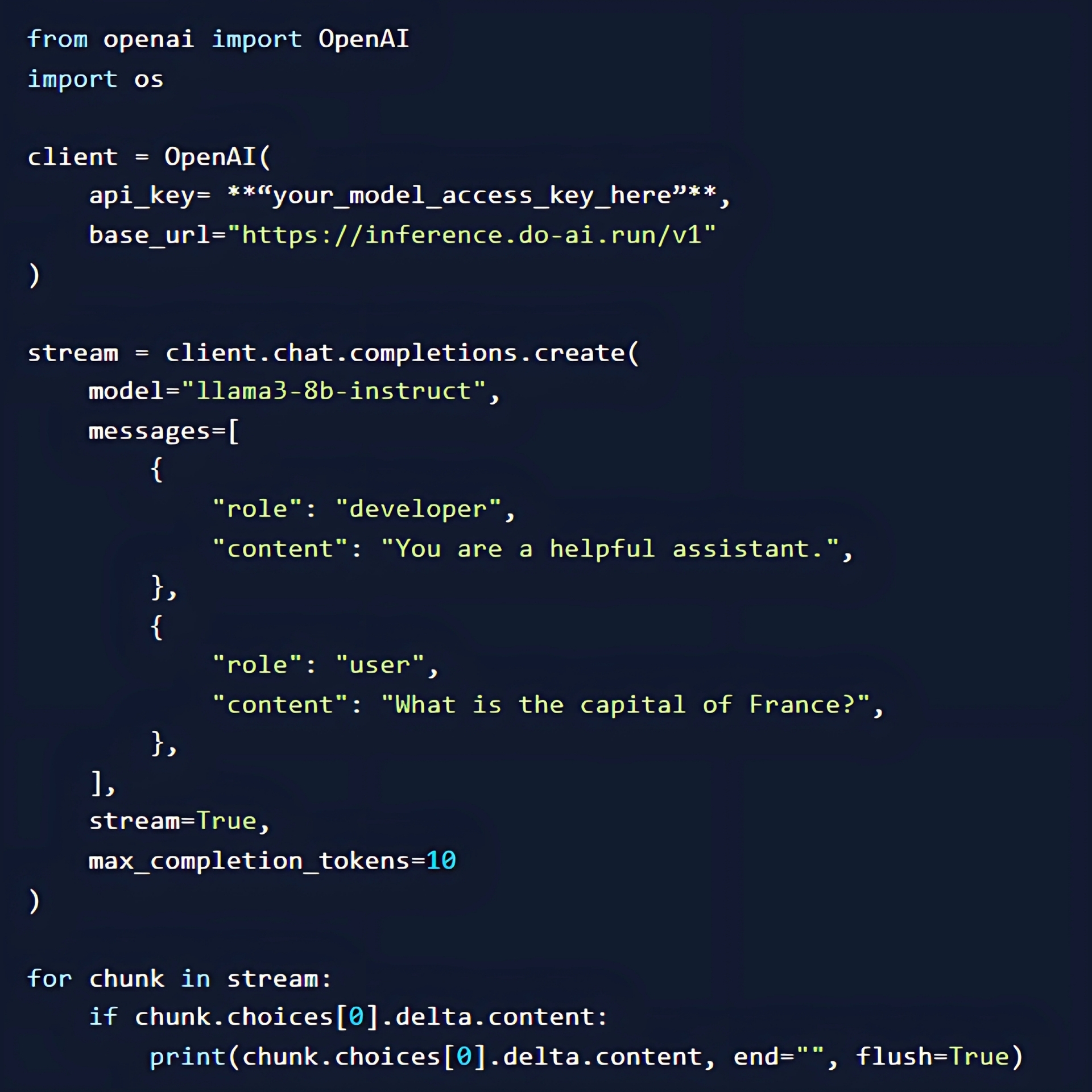
Kết quả bạn nhận được sẽ là “Thủ đô của Pháp là Paris”. Bạn nên thay đổi các giá trị như “max_completion_tokens” để phù hợp hơn với yêu cầu của mình. Chúng ta cũng có thể chỉnh sửa giá trị model ở dòng 10 thành bất kỳ mô hình nào có sẵn trong danh mục mô hình của DigitalOcean GradientAI Platform. Danh sách mô hình này liên tục được cập nhật để phản ánh sự phát triển của ngành, vì vậy hãy thường xuyên kiểm tra để biết các cập nhật mới nhất nhé.
Các Trường Hợp Ứng Dụng Serverless Inference từ DigitalOcean GradientAI Platform
Giờ đây, khi chúng ta đã thiết lập môi trường để chạy Serverless Inference, có vô số hoạt động tiềm năng mà chúng ta có thể sử dụng mô hình này. Từ mọi khả năng của một Mô hình Ngôn ngữ Lớn (LLM), chúng ta có thể tạo ra các ứng dụng thông minh mạnh mẽ, tận dụng sức mạnh của mô hình AI. Một số trường hợp ứng dụng khả thi bao gồm:
- Ứng dụng định hướng sự kiện: Khi một sự kiện cụ thể kích hoạt quá trình chạy của LLM, đây là điều phổ biến trong các trường hợp sử dụng ứng dụng thông minh (agentic use cases).
- Dịch vụ backend có khả năng mở rộng: Khi cần mở rộng khả năng suy luận ở backend vô thời hạn, điện toán không máy chủ (serverless) có thể đảm bảo người dùng của bạn sẽ không bao giờ phải chờ đợi.
- Xử lý dữ liệu: Các tác vụ xử lý hàng loạt (batch jobs) và xử lý dữ liệu có thể được thực hiện hiệu quả và năng suất mà không yêu cầu thiết lập tốn kém.
Và còn rất nhiều ứng dụng khác nữa!
Serverless Inference chính là giải pháp tối ưu cho các doanh nghiệp đang tìm kiếm giải pháp dựa trên LLM mà không phải lo lắng về việc tuyển dụng hay học hỏi các bước triển khai máy chủ riêng. Với Nền tảng GradientAI của DigitalOcean, việc truy cập Serverless Inference từ các GPU NVIDIA mạnh mẽ giờ đây trở nên dễ dàng hơn bao giờ hết!
Đọc thêm: GradientAI Platform – Đột Phá Mới Trong Phát Triển AI
Liên hệ CloudAZ ngay hôm nay để nhận tư vấn chuyên sâu về giải pháp AI từ DigitalOcean!









