Mỗi khi một ứng dụng AI tạo ra phản hồi hoặc phát hiện một giao dịch gian lận, hệ thống đang thực hiện AI Inference. Trong quá trình này, một mô hình đã được huấn luyện tiếp nhận dữ liệu mới và đưa dữ liệu đó đi qua các lớp tham số đã học để tạo ra kết quả đầu ra. Toàn bộ quy trình diễn ra chỉ trong vài mili-giây và có thể lặp lại hàng triệu lần mỗi ngày.
Tuy nhiên, tốc độ này đi kèm với chi phí đáng kể. Mỗi yêu cầu AI Inference đều tiêu tốn tài nguyên tính toán GPU và băng thông bộ nhớ, với mức độ sử dụng tăng theo kích thước mô hình và lưu lượng truy cập. Độ trễ tăng cao có thể gây ảnh hưởng trực tiếp đến trải nghiệm người dùng, trong khi chi phí GPU thường tăng nhanh hơn dự kiến. Bên cạnh đó, việc mở rộng khối lượng công việc trên nhiều khu vực địa lý còn tạo ra những thách thức về hạ tầng mà nhiều đội ngũ kỹ thuật chưa lường trước. Theo báo cáo nghiên cứu DigitalOcean Currents 2026, hoạt động AI Inference hiện đang tiêu tốn khoảng 76–100% ngân sách AI của nhiều tổ chức.
Đối với các doanh nghiệp đang triển khai mô hình học máy hoặc quy trình AI, yếu tố quan trọng không chỉ nằm ở cách mô hình học hỏi trong giai đoạn huấn luyện, mà còn ở khả năng phục vụ dự đoán một cách hiệu quả trong môi trường thời gian thực. Việc hiểu rõ AI Inference là gì và những yếu tố ảnh hưởng đến hiệu suất của nó sẽ giúp các tổ chức đưa ra quyết định kiến trúc hạ tầng thông minh hơn cho các dự án AI tiếp theo.
AI Inference là gì?
AI Inference là giai đoạn trong vòng đời của hệ thống AI, nơi một mô hình đã được huấn luyện sử dụng dữ liệu mới để đưa ra dự đoán hoặc tạo ra kết quả đầu ra. Đây chính là nền tảng vận hành của nhiều ứng dụng AI trong thực tế như hệ thống gợi ý nội dung, chẩn đoán y khoa hay các giao diện trò chuyện dựa trên mô hình ngôn ngữ lớn (LLM).
Trong môi trường sản xuất, AI Inference quyết định tốc độ người dùng nhận được kết quả, khả năng hệ thống xử lý các đợt tăng đột biến về lưu lượng truy cập, cũng như chi phí cần thiết để phục vụ mỗi lần dự đoán.
Sự khác biệt giữa AI Training và AI Inference
AI Training là giai đoạn mà mô hình học cách nhận diện và hiểu các mẫu dữ liệu. Trong quá trình này, hệ thống được cung cấp những tập dữ liệu khổng lồ và liên tục điều chỉnh hàng triệu tham số nội bộ để tối ưu khả năng dự đoán. Mô hình nhận dữ liệu đầu vào cùng với đáp án đúng (ví dụ: hình ảnh đã được gắn nhãn hoặc văn bản kèm kết quả mong đợi), sau đó đưa ra dự đoán, so sánh với đáp án thực tế và điều chỉnh để giảm sai số. Chu trình này lặp lại qua nhiều vòng cho đến khi mô hình đạt được độ chính xác cao. Đây là quá trình đòi hỏi năng lực tính toán rất lớn, nhưng thường chỉ diễn ra một lần hoặc theo các chu kỳ tái huấn luyện định kỳ.
Ngược lại, AI Inference là giai đoạn diễn ra sau khi mô hình đã được huấn luyện. Lúc này, mô hình đã hoàn chỉnh sẽ tiếp nhận dữ liệu mới mà nó chưa từng thấy trước đó và tạo ra dự đoán hoặc phản hồi trong thời gian thực.
So sánh AI Training và AI Inference
| Yếu tố | AI Training | AI Inference |
| Mục đích | Học các mẫu dữ liệu và tối ưu độ chính xác của mô hình | Tạo dự đoán hoặc kết quả đầu ra từ dữ liệu mới |
| Dữ liệu sử dụng | Tập dữ liệu lớn đã được gắn nhãn (ví dụ: giao dịch gian lận lịch sử, ảnh y khoa đã chú thích, đánh giá cảm xúc đã phân loại) | Dữ liệu đầu vào mới, chưa từng được mô hình xử lý |
| Kết quả đầu ra | Trọng số mô hình được cập nhật (mô hình đã huấn luyện hoàn chỉnh) | Dự đoán, điểm số, phân loại hoặc phản hồi được tạo ra |
| Yêu cầu tính toán | Rất cao (ví dụ: cụm GPU phân tán) | Thấp hơn cho mỗi yêu cầu nhưng nhạy cảm với độ trễ |
| Độ nhạy thời gian | Xử lý offline, không trực tiếp phục vụ người dùng | Thời gian thực hoặc gần thời gian thực, trực tiếp phục vụ người dùng |
| Tần suất | Không thường xuyên (huấn luyện ban đầu và tái huấn luyện) | Liên tục, xảy ra ở mọi yêu cầu |
| Cấu trúc chi phí | Chi phí huấn luyện ban đầu cao | Chi phí vận hành phát sinh theo từng yêu cầu |
| Trọng tâm tối ưu | Độ chính xác và giảm hàm mất mát | Độ trễ, thông lượng và hiệu quả chi phí |
Ví dụ: Hệ thống AI kiểm duyệt nội dung
Trong giai đoạn AI Training:
Hệ thống được huấn luyện với hàng triệu bài đăng đã được gắn nhãn như “an toàn”, “spam”, “ngôn từ thù ghét” hoặc “vi phạm chính sách”. Trong quá trình huấn luyện, mô hình học cách nhận diện các mẫu trong văn bản, giọng điệu, từ khóa và ngữ cảnh bằng cách điều chỉnh trọng số nội bộ để phân biệt nội dung gây hại với nội dung chấp nhận được.
Trong giai đoạn AI Inference:
Khi người dùng đăng một bài viết mới, mô hình đã huấn luyện sẽ xử lý văn bản trong thời gian thực và gán điểm xác suất cho từng loại nội dung. Dựa trên các điểm số này, hệ thống có thể tự động đăng tải bài viết, gắn cờ cảnh báo, hạn chế hiển thị hoặc chuyển bài viết sang quy trình kiểm duyệt thủ công.
Các môi trường triển khai AI Inference
AI Inference có thể được triển khai ở nhiều môi trường khác nhau tùy thuộc vào nhu cầu ứng dụng, mức độ nhạy cảm của dữ liệu và yêu cầu về hiệu năng. Quá trình suy luận có thể diễn ra trong các trung tâm dữ liệu đám mây tập trung, tại các điểm biên (edge) gần người dùng, hoặc trực tiếp trên thiết bị cục bộ.
Môi trường AI Inference trên Cloud
Môi trường cloud inference là lựa chọn phổ biến nhất cho các hệ thống AI trong môi trường sản xuất nhờ khả năng mở rộng tài nguyên tính toán, đặc biệt là GPU. Mô hình triển khai này hỗ trợ các framework phục vụ mô hình (model serving), hệ thống giám sát, cũng như tích hợp với API và các hệ thống phân tán.
Ví dụ, một nhóm phát triển triển khai hệ thống gợi ý (recommendation engine) có thể thiết lập kiến trúc như sau:
- Chạy dịch vụ inference trên GPU Droplets của DigitalOcean
- Triển khai API thông qua App Platform để cung cấp endpoint cho ứng dụng
- Lưu trữ metadata trong Managed PostgreSQL
- Lưu trữ các artifact của mô hình trong Spaces
Kiến trúc này cho phép hệ thống mở rộng linh hoạt khi lưu lượng truy cập tăng và đảm bảo hiệu năng ổn định cho các ứng dụng AI.
Môi trường AI Inference tại Edge
Edge inference thực hiện suy luận gần với nguồn dữ liệu, chẳng hạn tại cửa hàng bán lẻ, nhà máy hoặc trạm viễn thông. Cách tiếp cận này giúp giảm độ trễ và hạn chế lượng dữ liệu cần truyền về trung tâm.
Đối với các ứng dụng như phân tích video hoặc giám sát IoT, việc xử lý dữ liệu cục bộ cho phép hệ thống đưa ra quyết định chỉ trong vài mili-giây, thay vì phụ thuộc vào quá trình truyền dữ liệu qua lại với máy chủ đám mây.
Ví dụ trong môi trường bán lẻ:
Một camera an ninh theo dõi khu vực thanh toán. Một thiết bị edge nhỏ được lắp đặt tại cửa hàng chạy mô hình thị giác máy tính (computer vision) để phát hiện hành vi đáng ngờ, chẳng hạn như bỏ qua bước thanh toán. Khi phát hiện dấu hiệu bất thường, hệ thống lập tức gửi cảnh báo cho nhân viên cửa hàng. Các báo cáo tổng hợp và phân tích theo ngày sau đó mới được tải lên hệ thống trung tâm để phục vụ đánh giá tổng thể.
AI Inference trực tiếp trên thiết bị (On-device)
On-device inference diễn ra trực tiếp trên phần cứng của người dùng như điện thoại thông minh, laptop hoặc các hệ thống nhúng. Mô hình này hướng đến ba mục tiêu chính: tăng cường quyền riêng tư, giảm phụ thuộc vào kết nối mạng và đảm bảo phản hồi tức thì cho người dùng.
Ví dụ trong trợ lý giọng nói:
Khi người dùng nói một cụm từ kích hoạt như “Hey assistant”, một mô hình mạng nơ-ron chạy cục bộ trên thiết bị liên tục lắng nghe để nhận diện cụm từ này. Âm thanh được xử lý theo thời gian thực bằng CPU hoặc chip AI chuyên dụng trên thiết bị. Khi từ khóa kích hoạt được phát hiện, hệ thống mới gửi yêu cầu lên đám mây để xử lý sâu hơn.
Trong kiến trúc này:
- Mô hình nhận diện từ khóa đã được huấn luyện và lưu trực tiếp trên thiết bị
- Quá trình inference chạy liên tục trên phần cứng cục bộ
- Dữ liệu âm thanh thô không rời khỏi thiết bị nếu chưa được kích hoạt
- Trợ lý có thể phản hồi ngay lập tức, ngay cả khi không có kết nối Internet
Cách lựa chọn môi trường AI Inference phù hợp
Môi trường AI Inference phù hợp phụ thuộc vào nhiều yếu tố như yêu cầu độ trễ, lưu lượng truy cập, mức độ nhạy cảm của dữ liệu và giới hạn chi phí. Trong nhiều hệ thống thực tế, các đội ngũ kỹ thuật thường triển khai mô hình hybrid, kết hợp xử lý trên thiết bị hoặc edge với hệ thống inference trên cloud.
Chọn cloud inference khi:
- Cần khả năng mở rộng lớn
- Muốn quản lý mô hình tập trung
- Phải xử lý lưu lượng truy cập lớn hoặc khối lượng tính toán GPU cao
Chọn edge inference khi:
- Ứng dụng yêu cầu độ trễ rất thấp gần nguồn dữ liệu
- Cần giảm băng thông truyền dữ liệu về trung tâm
- Phải xử lý dữ liệu thời gian thực tại nhiều địa điểm phân tán
Chọn on-device inference khi:
- Quyền riêng tư của dữ liệu là yếu tố quan trọng
- Ứng dụng cần hoạt động offline
- Cần phản hồi tức thì trên thiết bị người dùng như smartphone hoặc thiết bị IoT.
Lợi ích của AI Inference
AI Inference đóng vai trò quyết định tốc độ phản hồi của ứng dụng, khả năng mở rộng hệ thống cũng như hiệu quả quản lý chi phí hạ tầng. Khi được triển khai đúng cách, AI Inference mang lại nhiều lợi ích rõ rệt về hiệu năng và vận hành:
Ra quyết định theo thời gian thực
AI Inference liên tục chuyển đổi dữ liệu trực tiếp thành các kết quả có cấu trúc như điểm rủi ro, phân loại, xếp hạng hoặc văn bản được tạo ra. Những kết quả này sau đó được tích hợp vào các ứng dụng để hỗ trợ ra quyết định.
Ví dụ, các mô hình phát hiện bất thường (anomaly detection) có thể nhận diện hoạt động đáng ngờ ngay trong thời gian thực, từ đó kích hoạt cảnh báo tự động và giúp đội ngũ vận hành phản ứng nhanh hơn.
Tối ưu chi phí sử dụng mô hình
Sau khi mô hình được huấn luyện hoàn chỉnh, nó có thể phục vụ hàng triệu dự đoán mà không cần huấn luyện lại. Dù AI Inference có thể trở nên tốn kém khi triển khai ở quy mô lớn, các kỹ thuật như batching hoặc quantization giúp giảm chi phí cho mỗi yêu cầu, đặc biệt trong các hệ thống có lưu lượng cao như trợ lý AI dựa trên mô hình ngôn ngữ lớn (LLM).
Cải thiện trải nghiệm người dùng
Độ trễ thấp trong quá trình inference ảnh hưởng trực tiếp đến cảm nhận của người dùng về mức độ “thông minh” của ứng dụng. Nếu một tính năng AI phản hồi trong khoảng 100 mili-giây thay vì 2 giây, người dùng sẽ đánh giá sản phẩm là nhanh, ổn định và đáng tin cậy hơn.
Khả năng mở rộng trong môi trường sản xuất
Khi lưu lượng truy cập tăng, các pipeline AI Inference có thể mở rộng theo chiều ngang nhờ hạ tầng phân tán và cơ chế tự động mở rộng (autoscaling).
Ví dụ, một trợ lý viết nội dung AI tích hợp trong nền tảng SaaS có thể phục vụ vài trăm người dùng trong giờ hoạt động bình thường, nhưng vẫn có thể xử lý hàng chục nghìn người dùng khi sản phẩm được ra mắt hoặc chiến dịch marketing tạo ra lưu lượng truy cập lớn.
Thử nghiệm và cải tiến mô hình nhanh hơn
Các pipeline inference cho phép đội ngũ kỹ thuật thử nghiệm và triển khai phiên bản mô hình mới mà không cần huấn luyện lại từ đầu. Doanh nghiệp có thể:
- Thực hiện A/B testing bằng cách phục vụ hai mô hình khác nhau cho các nhóm người dùng khác nhau
- Triển khai shadow deployment để đánh giá mô hình mới với lưu lượng thực nhưng không ảnh hưởng đến người dùng
- Áp dụng canary release để chuyển dần lưu lượng truy cập sang phiên bản mô hình mới trước khi triển khai toàn bộ
Nhờ đó, quá trình cải tiến và tối ưu mô hình AI có thể diễn ra nhanh hơn và an toàn hơn trong môi trường sản xuất.
Những thách thức của AI Inference
Khi các mô hình AI được đưa từ giai đoạn thử nghiệm sang môi trường sản xuất, AI Inference bắt đầu bộc lộ nhiều thách thức về vận hành và hạ tầng. Việc triển khai ở quy mô lớn đòi hỏi các tổ chức phải cân nhắc kỹ lưỡng giữa chi phí, hiệu năng và giới hạn của hệ thống.
Chi phí inference cao ở quy mô lớn
Theo báo cáo DigitalOcean Currents 2026, khoảng 49% người tham gia khảo sát cho biết chi phí inference là một trong những thách thức lớn nhất. Việc sử dụng GPU liên tục, mô hình định giá theo token, cùng với các mô hình lưu lượng truy cập khó dự đoán khiến chi phí vận hành tăng nhanh khi hệ thống mở rộng.
Độ nhạy với độ trễ trong môi trường sản xuất
Các ứng dụng thời gian thực yêu cầu phản hồi có độ trễ thấp và ổn định ngay cả khi lưu lượng truy cập biến động. Bất kỳ điểm nghẽn nào trong quá trình phục vụ mô hình (model serving), mạng hoặc cấp phát phần cứng đều có thể làm suy giảm trải nghiệm người dùng và ảnh hưởng đến độ tin cậy của hệ thống.
Độ phức tạp của hạ tầng và điều phối hệ thống
Nhiều đội ngũ kỹ thuật phải sử dụng nhiều công cụ và API khác nhau để vận hành AI Inference, từ đó làm tăng độ phức tạp trong vận hành. Các nhiệm vụ như điều phối triển khai, cấu hình autoscaling và giám sát hệ thống phân tán đòi hỏi chuyên môn sâu về lập lịch GPU (GPU scheduling), cân bằng tải (load balancing) và quản lý hạ tầng AI.
Yêu cầu cao về độ ổn định trong môi trường sản xuất
Các pipeline inference cần duy trì sự ổn định khi hệ thống chịu tải lớn, đồng thời đảm bảo tính nhất quán của kết quả đầu ra. Ví dụ, nếu các node GPU xử lý suy luận cho hệ thống hỗ trợ dựng video gặp sự cố khi nhiều người dùng truy cập đồng thời, các phiên chỉnh sửa video đang hoạt động có thể bị gián đoạn hoặc bản xem trước (preview) có thể bị treo.
Các loại AI Inference
AI Inference có thể được phân loại dựa trên cách thức và thời điểm hệ thống tạo ra dự đoán. Một số hệ thống phản hồi ngay lập tức khi nhận đầu vào từ người dùng, trong khi những hệ thống khác xử lý khối lượng dữ liệu lớn theo chu kỳ hoặc liên tục khi có sự kiện phát sinh.
Sự khác biệt giữa các loại AI Inference thường dựa trên ba yếu tố chính:
- Thời điểm xử lý yêu cầu (Request timing): Dự đoán được tạo ra ngay lập tức theo từng yêu cầu, theo lịch định kỳ, hoặc liên tục khi dữ liệu mới xuất hiện.
- Mô hình luồng dữ liệu (Data flow pattern): Dữ liệu đi qua hệ thống theo dạng phản hồi từng yêu cầu, xử lý dữ liệu hàng loạt hoặc luồng sự kiện liên tục.
- Yêu cầu về độ phản hồi (Responsiveness requirements): Thời gian phản hồi chấp nhận được của ứng dụng, có thể là mili-giây đối với hệ thống thời gian thực hoặc chậm hơn đối với các tác vụ không khẩn cấp.
Real-time (Online) Inference
Real-time inference xử lý từng yêu cầu ngay khi phát sinh và trả về kết quả dự đoán gần như ngay lập tức. Mô hình này tuân theo kiến trúc request–response, trong đó mỗi hành động của người dùng hoặc mỗi API call sẽ kích hoạt một lần dự đoán của mô hình.
Thời gian phản hồi thường dao động từ vài mili-giây đến vài giây, tùy thuộc vào độ phức tạp của mô hình và năng lực hạ tầng.
Streaming Inference
Streaming inference liên tục đánh giá các luồng dữ liệu đang được truyền vào hệ thống thay vì chờ từng yêu cầu riêng lẻ hoặc các tác vụ theo lịch. Dữ liệu được xử lý theo mô hình event-driven và các dự đoán được tạo ra gần như theo thời gian thực khi dữ liệu mới xuất hiện.
Về tốc độ phản hồi, streaming inference nằm giữa real-time inference và batch inference: nhanh hơn các tác vụ xử lý theo lô định kỳ, nhưng hoạt động trên luồng dữ liệu liên tục thay vì từng yêu cầu riêng lẻ.
Batch Inference
Batch inference thực hiện dự đoán trên khối lượng dữ liệu lớn theo các chu kỳ định kỳ. Hệ thống xử lý dữ liệu theo dạng bulk processing, thường thông qua các tác vụ được lên lịch có thể kéo dài từ vài phút đến vài giờ.
Các workload này thường được điều phối bởi job scheduler hoặc workflow engine, sau đó chạy trên các cụm tính toán phân tán. Dữ liệu được đọc từ hệ thống lưu trữ, xử lý song song và ghi lại dưới dạng bảng dữ liệu, tệp hoặc bản ghi trong cơ sở dữ liệu.
So sánh các loại AI Inference
| Loại | Mô tả | Thời gian phản hồi | Luồng dữ liệu | Trường hợp sử dụng |
| Real-time (online) inference | Xử lý từng yêu cầu ngay khi phát sinh | Mili-giây đến vài giây | Request–response | Chatbot, phát hiện gian lận, hệ thống gợi ý |
| Streaming inference | Đánh giá liên tục các luồng dữ liệu đến | Gần thời gian thực | Luồng dữ liệu sự kiện liên tục | Giám sát IoT, phát hiện sự kiện tài chính, phát hiện bất thường |
| Batch inference | Chạy dự đoán trên tập dữ liệu lớn theo lịch | Vài phút đến vài giờ | Xử lý dữ liệu hàng loạt | Chấm điểm tín dụng, báo cáo phân tích, đánh giá mô hình định kỳ |
Cách AI Inference hoạt động
Quá trình AI Inference diễn ra thông qua một tầng phục vụ mô hình (model serving layer). Tầng này chịu trách nhiệm tiếp nhận yêu cầu, thực hiện tính toán (trên CPU hoặc GPU) và trả kết quả thông qua API hoặc một định dạng dữ liệu cụ thể.
Để hiểu rõ hơn, hãy xem cách một hệ thống phát hiện gian lận thẻ tín dụng đánh giá một giao dịch trong thực tế.
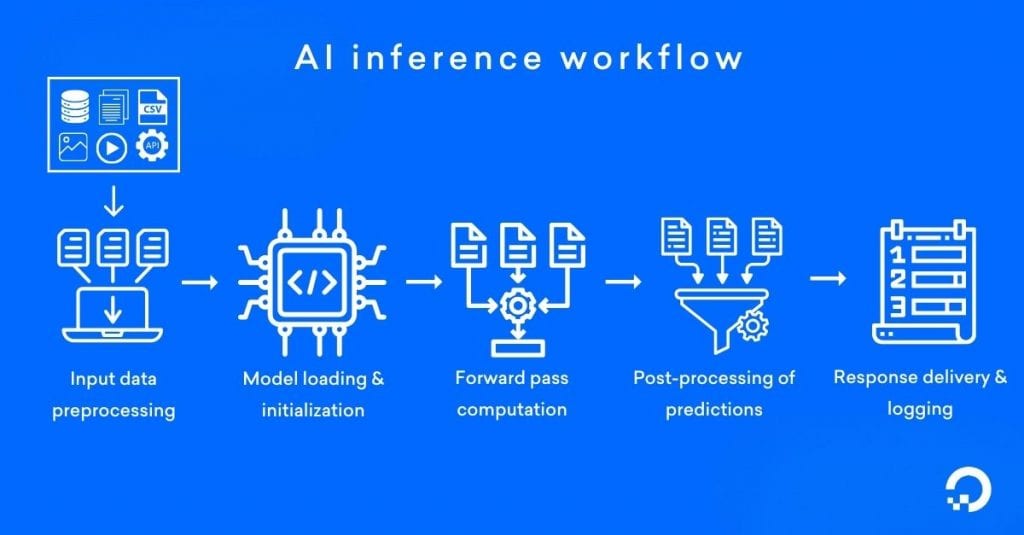
Tiền xử lý dữ liệu đầu vào (Input Data Preprocessing)
Các dữ liệu đầu vào thô như văn bản, hình ảnh, âm thanh hoặc dữ liệu có cấu trúc sẽ được kiểm tra và chuyển đổi sang định dạng mà mô hình có thể xử lý. Quá trình này có thể bao gồm:
- Tokenization (đối với mô hình ngôn ngữ lớn – LLM)
- Chuẩn hóa dữ liệu (normalization)
- Trích xuất đặc trưng (feature extraction)
- Chuyển đổi dữ liệu thành tensor hoặc vector số
Ví dụ:
Một khách hàng quẹt thẻ tín dụng để mua thiết bị điện tử trị giá 2.400 USD tại một cửa hàng ở São Paulo, trong khi tài khoản của họ được đăng ký tại Chicago, và thiết bị sử dụng cho giao dịch chưa từng xuất hiện trước đó trong hệ thống.
Hệ thống sẽ trích xuất các đặc trưng có cấu trúc từ giao dịch như:
- Giá trị giao dịch
- Danh mục cửa hàng
- Dấu vân tay thiết bị (device fingerprint)
- Vị trí địa lý
- Thời điểm giao dịch
- Lịch sử chi tiêu gần đây
Các đặc trưng này được chuẩn hóa và chuyển thành vector đặc trưng dạng số, sẵn sàng cho mô hình xử lý.
Tải và khởi tạo mô hình (Model Loading and Initialization)
Mô hình đã được huấn luyện – bao gồm kiến trúc mạng và các trọng số đã học – sẽ được tải vào bộ nhớ. Trong môi trường sản xuất, các mô hình thường được đóng gói container và phục vụ thông qua các framework như:
- TensorFlow Serving
- TorchServe
- Hoặc các dịch vụ tùy chỉnh dựa trên FastAPI
Trong ví dụ này, một mạng nơ-ron phát hiện gian lận đã được huấn luyện trước đang chạy trong bộ nhớ thông qua một model server containerized sử dụng TorchServe. Khi giao dịch phát sinh, API gateway sẽ định tuyến vector đặc trưng đến endpoint của mô hình.
Tính toán forward pass (Forward Pass Computation)
Dữ liệu đã được xử lý sẽ đi qua mô hình, nơi các phép nhân ma trận và hàm kích hoạt (activation functions) được thực hiện để tạo ra kết quả dự đoán.
Đối với các mô hình deep learning hoặc LLM, bước này thường chạy trên GPU hoặc phần cứng tăng tốc chuyên dụng để tối ưu độ trễ và thông lượng.
Trong ví dụ phát hiện gian lận:
Mô hình xử lý vector đặc trưng thông qua các lớp mạng của nó và đánh giá sự kết hợp giữa:
- Thiết bị chưa từng được nhận diện
- Vị trí giao dịch quốc tế
- Giá trị giao dịch cao
Những yếu tố này được so sánh với các mẫu đã học từ hàng triệu giao dịch lịch sử. Kết quả đầu ra của mô hình là điểm xác suất gian lận (fraud probability score) = 0,92.
Hậu xử lý kết quả dự đoán (Post-processing of Predictions)
Kết quả thô từ mô hình sẽ được chuyển thành dạng có thể sử dụng trong ứng dụng, chẳng hạn như:
- Điểm xác suất
- Nhãn phân loại
- Danh sách xếp hạng
- Chuỗi văn bản được tạo ra
Trong bước này, hệ thống có thể áp dụng:
- Ngưỡng quyết định (thresholding)
- Chiến lược giải mã (decoding strategies) như greedy decoding hoặc beam search
- Quy tắc nghiệp vụ (business rules)
Trong ví dụ này, một rule engine sẽ diễn giải điểm 0,92 dựa trên logic của hệ thống. Vì điểm này vượt ngưỡng 0,85 và giao dịch diễn ra ở quốc gia khác, hệ thống phân loại giao dịch là rủi ro cao và yêu cầu xác thực bổ sung thay vì từ chối ngay lập tức.
Trả kết quả và ghi log (Response Delivery and Logging)
Kết quả cuối cùng sẽ được gửi đến:
- API
- Cơ sở dữ liệu
- Hoặc các hệ thống downstream như Kafka streams, payment gateways hoặc hệ thống cảnh báo.
Đồng thời, các chỉ số quan trọng cũng được ghi lại để phục vụ giám sát và tối ưu hiệu năng, bao gồm:
- Độ trễ (latency) – ví dụ P95 / P99
- Thông lượng (throughput)
- Tỷ lệ lỗi (error rate)
Trong kịch bản trên, chỉ trong khoảng 120 mili-giây sau khi thẻ được quẹt, cổng thanh toán nhận được phân loại rủi ro cao và kích hoạt yêu cầu xác thực OTP gửi đến điện thoại của khách hàng.
Cùng lúc đó, hệ thống ghi lại:
- Điểm dự đoán của mô hình
- Metadata của giao dịch
- Độ trễ xử lý (P95)
- Kết quả xác thực
Những dữ liệu này sẽ được sử dụng cho giám sát hệ thống và tái huấn luyện mô hình trong tương lai.
Các chỉ số hiệu năng quan trọng cho AI Inference
Việc tối ưu AI Inference bắt đầu từ việc xác định đúng các chỉ số cần theo dõi. Không phải tất cả các chỉ số đều có mức độ quan trọng như nhau đối với mọi trường hợp sử dụng, nhưng bỏ qua bất kỳ chỉ số nào cũng có thể dẫn đến độ trễ cao, lãng phí tài nguyên tính toán hoặc chi phí vận hành tăng ngoài dự kiến.
Dưới đây là những chỉ số hiệu năng quan trọng nhất trong hệ thống AI Inference:
| Chỉ số hiệu năng | Mô tả | Vì sao quan trọng | Ví dụ |
| Latency (Độ trễ) | Thời gian cần thiết để tạo ra dự đoán cho một yêu cầu | Quyết định tốc độ phản hồi mà người dùng cảm nhận; các chỉ số tail latency như P95/P99 phản ánh độ trễ trong các tình huống tải cao | Một chatbot phản hồi trung bình trong 120 ms, nhưng tăng lên 2 giây ở P99 khi lưu lượng truy cập cao |
| Throughput (Thông lượng) | Số lượng yêu cầu xử lý mỗi giây (RPS) hoặc số token tạo ra mỗi giây đối với LLM | Cho biết hệ thống có thể xử lý bao nhiêu lưu lượng trước khi hiệu năng bắt đầu suy giảm | Một LLM tạo 80 token/giây so với 20 token/giây sẽ tạo khác biệt lớn về tốc độ phản hồi khi vận hành ở quy mô lớn |
| Cost per request (Chi phí mỗi yêu cầu) | Chi phí tài nguyên tính toán cho mỗi lần inference | Ảnh hưởng trực tiếp đến hiệu quả kinh tế khi vận hành hệ thống ở quy mô lớn | Một hệ thống inference chạy trên GPU có chi phí 0,002 USD/yêu cầu so với 0,02 USD/yêu cầu khi lưu lượng tăng cao |
| Hardware utilization (Mức sử dụng phần cứng) | Mức độ sử dụng hiệu quả CPU, GPU hoặc các bộ tăng tốc | Mức sử dụng thấp gây lãng phí tài nguyên và làm tăng chi phí cho mỗi dự đoán | Một GPU chỉ chạy ở 30% công suất sẽ làm lãng phí năng lực tính toán và tăng chi phí cho mỗi lần dự đoán |
| Scalability under load (Khả năng mở rộng khi tải tăng) | Khả năng duy trì hiệu năng ổn định khi lưu lượng truy cập tăng đột biến | Đảm bảo hệ thống vẫn hoạt động ổn định và duy trì độ trễ thấp trong thời điểm cao điểm | Hệ thống gợi ý sản phẩm của một nền tảng thương mại điện tử vẫn hoạt động ổn định trong thời gian Black Friday mà không xảy ra tăng đột biến độ trễ |
Các trường hợp ứng dụng của AI Inference
AI Inference bắt đầu phát huy giá trị ngay khi ứng dụng thực sự phản hồi lại người dùng. Dù là chấm điểm một giao dịch, xếp hạng kết quả tìm kiếm hay tạo nội dung, inference chính là tầng thực thi biến khả năng học của mô hình thành các hành động trực tiếp trong ứng dụng.
Phát hiện gian lận trong giao dịch tài chính
Trong lĩnh vực thanh toán, AI Inference được sử dụng để phát hiện gian lận theo thời gian thực. Một công ty hệ thống thanh toán tại Hoa Kỳ, H2O.ai, triển khai các mô hình deep learning được huấn luyện trên 160 triệu bản ghi dữ liệu với khoảng 1.500 đặc trưng nhằm nhận diện giao dịch gian lận.
Khi một giao dịch mới được khởi tạo, mô hình đã triển khai sẽ chấm điểm rủi ro chỉ trong vài mili-giây. Hệ thống có thể ngay lập tức chặn hoặc gắn cờ những giao dịch đáng ngờ trước khi quá trình thanh toán được xác nhận.
Phân tích hình ảnh y khoa
Trong lĩnh vực y tế, AI Inference đóng vai trò quan trọng trong phân tích hình ảnh y khoa. Một nghiên cứu về phát hiện khối u não minh họa rõ cách hệ thống inference hoạt động trong thực tế.
Các ảnh chụp MRI được:
- Gắn nhãn dữ liệu
- Thu nhỏ về kích thước 150 × 150 pixel
- Chuẩn hóa dữ liệu
Sau đó được đưa vào một mạng nơ-ron tích chập (CNN) được tùy chỉnh. Trong giai đoạn inference, mô hình phân loại mỗi ảnh quét thành có khối u hoặc không có khối u với độ chính xác kiểm chứng đạt 98,67%.
Để hỗ trợ bác sĩ trong quá trình ra quyết định lâm sàng, các kỹ thuật hậu xử lý như SHAP, LIME và Grad-CAM được sử dụng để tạo bản đồ nhiệt trực quan, làm nổi bật các vùng ảnh có ảnh hưởng lớn đến dự đoán của mô hình.
Hệ thống tìm kiếm và gợi ý nội dung
Trong các hệ thống tìm kiếm và gợi ý, AI Inference giúp xếp hạng kết quả theo mức độ liên quan trong thời gian thực.
Khi người dùng gửi truy vấn hoặc truy cập một trang nội dung, các đặc trưng ngữ cảnh như:
- Lịch sử nhấp chuột
- Hành vi trong phiên truy cập
- Metadata nội dung
sẽ được mã hóa thành dữ liệu đầu vào cho mô hình. Mô hình xếp hạng sau đó chấm điểm nhiều ứng viên nội dung cùng lúc, và hệ thống inference sẽ sắp xếp chúng dựa trên điểm liên quan dự đoán.
Ví dụ, Netflix sử dụng kiến trúc hai giai đoạn:
- Retrieval stage: sử dụng dữ liệu hành vi trong phiên, lịch sử duyệt và sở thích dài hạn để chọn ra tập nội dung ứng viên.
- Ranking stage: một mô hình deep learning tính toán điểm liên quan cho từng nội dung và trả về danh sách xếp hạng trong khoảng 40 mili-giây.
Nhận thức môi trường cho xe tự hành
Trong lĩnh vực xe tự hành, AI Inference giúp hệ thống nhận diện và hiểu môi trường xung quanh trong thời gian thực.
Công ty Tata Elxsi đã tích hợp AI với các cảm biến LiDAR tầm xa (lên tới 1 km) hoạt động ở tần số 10 Hz để hỗ trợ hệ thống nhận thức của xe tự hành.
Dữ liệu từ:
- LiDAR
- Camera
được kết hợp và chuyển đổi thành tensor, sau đó đưa vào các mô hình deep learning để thực hiện inference. Hệ thống có thể:
- Phát hiện phương tiện và người đi bộ
- Nhận diện biển báo giao thông
- Phân vùng khu vực có thể lái xe
Các kết quả như phân loại đối tượng, ước lượng khoảng cách và phát hiện vi phạm (ví dụ: đi sai làn hoặc chạy quá tốc độ) được gửi trực tiếp đến hệ thống giám sát và điều khiển để hỗ trợ ra quyết định lái xe trong các điều kiện ánh sáng và thời tiết khác nhau.
Generative AI và sáng tạo nội dung
AI Inference cũng là nền tảng của các hệ thống Generative AI. Nền tảng AI Writer triển khai các mô hình ngôn ngữ lớn (LLM) với 40 tỷ tham số để tạo nội dung marketing và tài liệu doanh nghiệp.
Trong kiến trúc này:
- Prompt của người dùng được gửi qua API
- Mô hình chạy trên GPU được phục vụ thông qua NVIDIA Triton Inference Server
- Phản hồi được tạo token-by-token
Hệ thống inference của nền tảng này có thể xử lý tới một nghìn tỷ API call mỗi tháng và tạo ra khoảng 90.000 từ mỗi giây.
Hạ tầng inference thế hệ mới
Để xây dựng hệ thống AI Inference có khả năng mở rộng cho Generative AI, các kỹ sư tại DigitalOcean sử dụng nhiều công nghệ như:
- Ray cho điều phối workload phân tán
- vLLM để tối ưu suy luận LLM
- Kubernetes để quản lý hạ tầng container và autoscaling
Các kỹ thuật như serverless inference, dynamic batching và chiến lược tối ưu KV-cache giúp cải thiện đáng kể hiệu năng GPU và khả năng mở rộng của hệ thống inference hiện đại.
Triển khai AI Inference hiệu năng cao với DigitalOcean
DigitalOcean Gradient™ AI Inference Cloud được xây dựng chuyên biệt để hỗ trợ các doanh nghiệp huấn luyện, tinh chỉnh (fine-tune) và triển khai AI Inference hiệu quả về chi phí cho các ứng dụng và agent AI hiệu năng cao.
Dù bạn đang triển khai các mô hình thời gian thực hay mở rộng khối lượng công việc của LLM trong môi trường sản xuất, DigitalOcean cung cấp nhiều lựa chọn hạ tầng inference phù hợp với từng loại workload:
GPU Droplets cung cấp các GPU NVIDIA và AMD theo nhu cầu (on-demand), phù hợp cho các hệ thống AI yêu cầu thông lượng cao và độ trễ thấp trong quá trình inference. Giải pháp này đặc biệt hữu ích cho các ứng dụng như chatbot, hệ thống gợi ý hoặc phân tích dữ liệu thời gian thực.
Bare Metal GPUs là các máy chủ GPU chuyên dụng dành riêng cho một khách hàng (single-tenant), giúp đảm bảo hiệu năng tối đa và tính ổn định cao cho các workload lớn hoặc nhạy cảm với hiệu năng. Đây là lựa chọn phù hợp cho những hệ thống AI quy mô lớn hoặc các ứng dụng yêu cầu tài nguyên GPU ổn định trong thời gian dài.
Gradient™ AI Platform là nền tảng hợp nhất cho phép truy cập vào các endpoint của nhiều mô hình AI hàng đầu – bao gồm cả mô hình độc quyền và mã nguồn mở – thông qua một API key duy nhất. Nền tảng này hỗ trợ các mô hình từ:
- OpenAI
- Anthropic
- Mistral
- Meta
Ngoài ra, Gradient™ còn cung cấp các tính năng hỗ trợ toàn bộ vòng đời phát triển AI, bao gồm:
- Knowledge base tích hợp
- Công cụ truy vết (traceability tools)
- Agent giám sát hệ thống (monitoring agents)
Mô hình tính phí được thiết kế theo mức sử dụng (usage-based pricing), giúp doanh nghiệp tránh chi phí cho tài nguyên không sử dụng.
Tìm hiểu thêm: Native .NET Buildpack Được Hỗ Trợ Trên DigitalOcean App Platform
ƯU ĐÃI ĐẶC BIỆT DÀNH CHO NGƯỜI DÙNG MỚI: CloudAZ hiện đang có chương trình tặng ngay $200 credit dùng thử hoàn toàn miễn phí trong 60 ngày cho các tài khoản DigitalOcean đăng ký mới. Liên hệ ngay CloudAZ để được tư vấn chi tiết!









