Nguồn gốc: Prompt Caching for Anthropic and OpenAI Models: Building Cost-Efficient AI Systems
Tác giả gốc: Satyam Namdeo – Chuyên gia tại DigitalOcean.
Ngày cập nhật: 02/04/2026.
Prompt Caching (Bộ nhớ đệm nhắc nhở) đã trở thành một kỹ thuật tối ưu hóa thiết yếu cho các mô hình Anthropic và OpenAI. Trong bài viết này, chúng ta sẽ tìm hiểu cách triển khai Prompt Caching trên DigitalOcean để xây dựng hệ thống AI hiệu quả, cắt giảm chi phí token từ 70–90% và giảm độ trễ tối đa.
Thách thức về chi phí khi mở rộng quy mô LLM
Các mô hình ngôn ngữ lớn (LLM) là nền tảng cho trợ lý ảo, công cụ RAG và hệ thống khắc phục sự cố. Tuy nhiên, khi ứng dụng mở rộng, một bài toán nan giải xuất hiện: chi phí token tăng vọt khi các dữ liệu tĩnh (hướng dẫn hệ thống, tài liệu tri thức) bị gửi đi gửi lại nhiều lần.
Việc xử lý lặp lại nội dung tĩnh không chỉ gây lãng phí tài nguyên tính toán mà còn làm tăng hóa đơn API hàng tháng của doanh nghiệp.
Prompt Caching là gì?
Bộ nhớ đệm lời nhắc là một cơ chế trong đó các phần lớn của lời nhắc vẫn giữ nguyên giữa các yêu cầu được lưu trữ và sử dụng lại , thay vì được xử lý lại mỗi lần.
Vì các thông tin như hướng dẫn hệ thống, sơ đồ công cụ, rào cản an toàn, tài liệu, v.v. hiếm khi thay đổi, việc gửi đi gửi lại nhiều lần sẽ lãng phí tài nguyên tính toán và làm tăng chi phí sử dụng token. Bộ nhớ đệm nhắc nhở giải quyết vấn đề này bằng cách:
- Lưu trữ các đoạn lời nhắc đã được xử lý trước đó.
- Tái sử dụng các phân đoạn đó khi các yêu cầu tương tự xuất hiện lại.
- Tính phí thấp hơn nhiều cho các token được lưu trong bộ nhớ cache.
Phương pháp tối ưu hóa này đặc biệt hiệu quả trong các hệ thống sản xuất, nơi các lời nhắc tĩnh lớn được kết hợp với các truy vấn động nhỏ.
Cơ chế hoạt động của Prompt Caching
Nhìn chung, cơ chế bộ nhớ đệm nhắc nhở hoạt động bằng cách xác định các mã tiền tố vẫn giữ nguyên giá trị trong nhiều yêu cầu khác nhau.
Nếu một yêu cầu bắt đầu bằng cùng một chuỗi mã thông báo như yêu cầu trước đó, nhà cung cấp mô hình có thể tái sử dụng biểu diễn đã được xử lý trước đó thay vì tính toán lại.
Quy trình làm việc diễn ra như sau:
- Trong yêu cầu ban đầu, toàn bộ lời nhắc được xử lý và các phân đoạn tĩnh được lưu trữ trong bộ nhớ cache.
- Trong khi đó, theo yêu cầu tiếp theo,
- Mô hình này phát hiện các mã thông báo tiền tố giống hệt nhau.
- Các mã thông báo được lưu trong bộ nhớ cache sẽ được sử dụng lại.
- Chỉ những mã thông báo mới được xử lý.
Cách tiếp cận này giúp giảm đáng kể khối lượng tính toán vì quá trình suy luận LLM tốn nhiều tài nguyên nhất khi xử lý các lời nhắc lớn .
Ưu điểm của Prompt Caching
Việc lưu trữ dữ liệu tức thời mang lại một số lợi ích quan trọng cho các hệ thống AI trong môi trường sản xuất.
Giảm chi phí đáng kể
Việc sử dụng bộ nhớ đệm nhắc nhở có thể giảm đáng kể chi phí vận hành các ứng dụng LLM vì các mã thông báo được tái sử dụng từ các yêu cầu trước đó được tính phí ở mức thấp hơn nhiều so với các mã thông báo được xử lý mới. Ví dụ, trong GPT-5, mã thông báo đầu vào tiêu chuẩn có giá khoảng 1,25 đô la cho mỗi triệu mã thông báo, trong khi mã thông báo đầu vào được lưu vào bộ nhớ đệm chỉ có giá 0,125 đô la cho mỗi triệu mã thông báo, khiến mã thông báo được lưu vào bộ nhớ đệm rẻ hơn khoảng 10 lần .
Giảm độ trễ
Vì các phân đoạn lời nhắc được lưu vào bộ nhớ cache không cần phải tính toán lại, mô hình có thể xử lý các yêu cầu nhanh hơn. Điều này cải thiện trải nghiệm người dùng trong các ứng dụng tương tác như Trợ lý trò chuyện, Trợ lý lập trình và công cụ Tìm kiếm tài liệu.
Khả năng mở rộng được cải thiện
Các ứng dụng xử lý lưu lượng truy cập lớn được hưởng lợi đáng kể vì bộ nhớ đệm giúp ngăn chặn việc tính toán dư thừa trên hàng nghìn yêu cầu.
Điều này giúp các hệ thống AI trở nên khả thi hơn về mặt kinh tế khi được triển khai trên quy mô lớn.
Các trường hợp sử dụng phổ biến mà Prompt Caching giúp ích cho người dùng
Việc lưu trữ lời nhắc hiệu quả nhất khi các phân đoạn lời nhắc lớn vẫn giữ nguyên tính nhất quán giữa các yêu cầu . Hầu hết các ứng dụng AI thường sử dụng phương pháp này bao gồm ChatGPT, Cursor, Perplexity AI, Notion AI.
Thế hệ tăng cường truy xuất (RAG)
Hệ thống RAG truy xuất tài liệu và chèn chúng vào các lời nhắc. Nếu các tài liệu được truy xuất được sử dụng lại thường xuyên, việc lưu trữ tạm thời có thể giảm đáng kể chi phí token.
Các ví dụ điển hình bao gồm Trợ lý Cơ sở Tri thức, Tìm kiếm Tài liệu, Chatbot hỗ trợ nội bộ, v.v.
Hệ thống khắc phục sự cố AI
Các công cụ hỗ trợ doanh nghiệp thường bao gồm hướng dẫn hệ thống, sổ tay vận hành và tài liệu kỹ thuật.
Các lời nhắc này có thể vượt quá vài nghìn token và rất lý tưởng để lưu vào bộ nhớ đệm.
Kiến trúc Prompt Caching áp dụng vào thực tế khi triển khai
Một kiến trúc phổ biến được sử dụng trong các hệ thống AI sản xuất là chia các lời nhắc thành các phần tĩnh và động.
Ý tưởng chính rất đơn giản: Đặt tất cả các thành phần nhắc nhở lớn, tĩnh ở đầu lời nhắc. Điều này tạo ra một tiền tố lớn có thể được lưu vào bộ nhớ cache.
Cached Prefix
Các thành phần nhắc nhở sau đây thường không thay đổi giữa các yêu cầu:
- Thông báo hệ thống (hướng dẫn dài)
- Sơ đồ công cụ
- Tài liệu RAG
Dynamic Portion
Các thành phần sau đây sẽ thay đổi theo yêu cầu:
- truy vấn của người dùng
- lịch sử cuộc trò chuyện
- đầu ra của công cụ
Kiến trúc hệ thống: Prompt Caching trong sản xuất
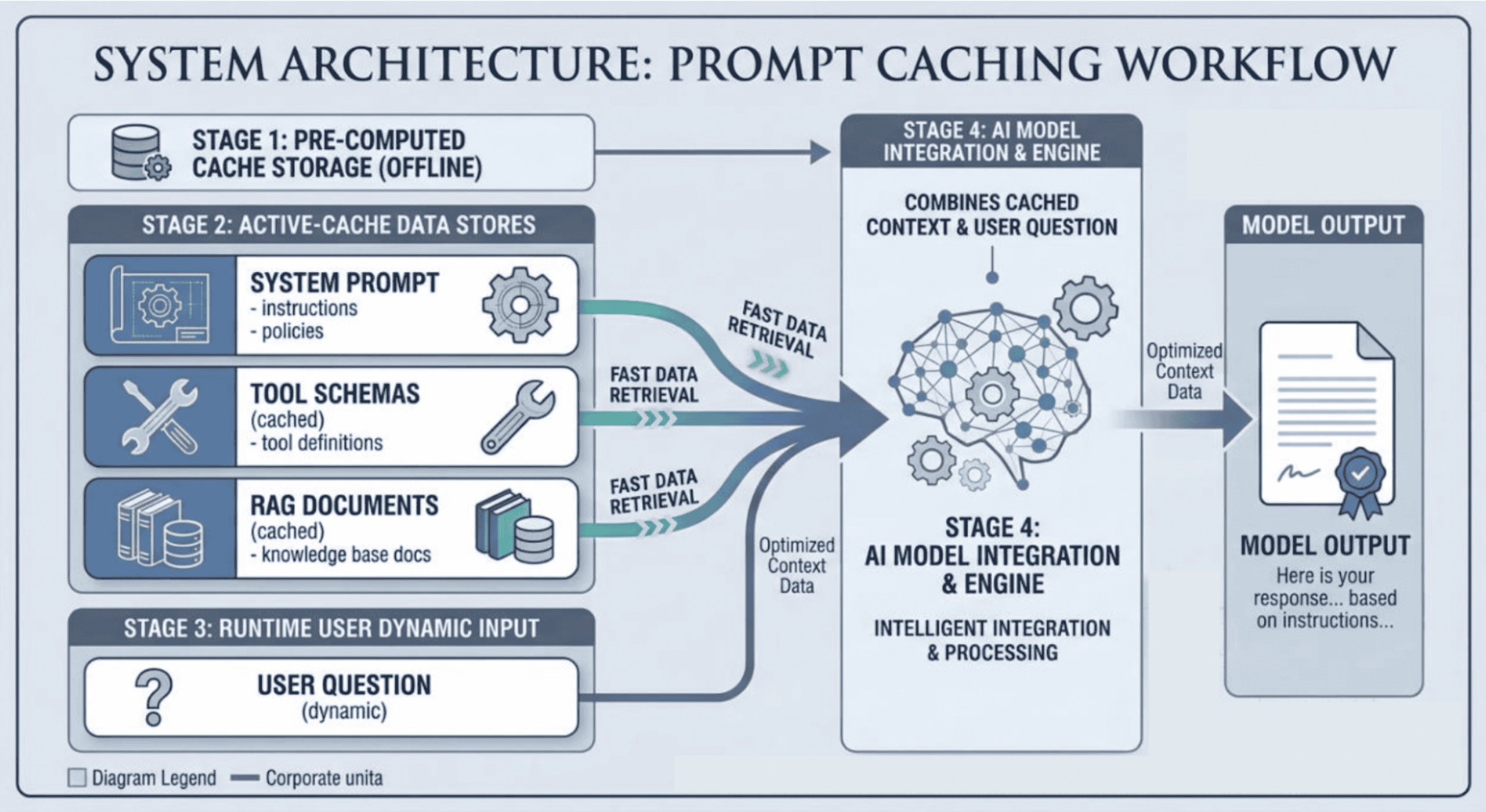
So sánh Prompt Caching trên Anthropic và OpenAI
Dưới đây là cách triển khai trên nền tảng DigitalOcean Gradient™ AI Inference Cloud:
Đối với Anthropic (Claude)
Anthropic cho phép bạn kiểm soát thủ công (Explicit Control). Bạn có thể đánh dấu chính xác đoạn nào cần cache bằng tham số cache_control. Điều này rất hữu ích cho các ứng dụng có hệ thống hướng dẫn (system prompt) cực kỳ phức tạp.

Đối với OpenAI (GPT)
OpenAI sử dụng cơ chế tự động hoàn toàn (Implicit Caching). Hệ thống sẽ tự nhận diện các đoạn tiền tố giống nhau trên 1024 tokens để đưa vào bộ nhớ đệm. Bạn không cần thay đổi code nhiều, OpenAI sẽ tự tối ưu hóa hóa đơn cho bạn.
Triển khai LLM tiết kiệm chi phí với DigitalOcean
DigitalOcean hỗ trợ bộ nhớ đệm tức thời khi sử dụng các mô hình từ các nhà cung cấp như Anthropic và OpenAI. Việc thanh toán tuân theo mức giá trên mỗi token do nhà cung cấp mô hình quy định.
Các nhà phát triển sử dụng DigitalOcean có thể:
- Cho phép các tham số điều khiển bộ nhớ đệm Anthropic
- Tận dụng khả năng lưu trữ ngầm định của OpenAI.
- Theo dõi việc sử dụng token trong các phản hồi API
Điều này cho phép các nhóm triển khai các hệ thống AI tiết kiệm chi phí trong khi sử dụng nền tảng phát triển của DigitalOcean. Bộ nhớ đệm tức thời đã trở thành một trong những kỹ thuật mạnh mẽ nhất để giảm chi phí cơ sở hạ tầng LLM.
Bằng cách sắp xếp các lời nhắc thành các tiền tố được lưu vào bộ nhớ đệm tĩnh và các thành phần yêu cầu động, các nhà phát triển có thể giảm chi phí mã thông báo khoảng 70–90% trong nhiều ứng dụng thực tế.
Ở quy mô lớn, những khoản tiết kiệm này có thể lên tới hàng chục hoặc hàng trăm nghìn đô la mỗi tháng . Khi các ứng dụng AI tiếp tục phát triển, các kiến trúc tích hợp bộ nhớ đệm tức thời sẽ trở thành một phần cốt lõi trong việc xây dựng các hệ thống AI hiệu quả và có khả năng mở rộng.
Đối với các nhóm xây dựng ứng dụng AI sản xuất trên các nền tảng như DigitalOcean, bộ nhớ đệm tức thời không chỉ là một biện pháp tối ưu hóa mà còn là nguyên tắc thiết kế nền tảng để triển khai LLM hiệu quả về chi phí.
Tìm hiểu thêm: https://cloudaz.io/van-hanh-nhieu-openclaw-ai-agents-khong-can-quan-ly-ha-tang/









