Hiện nay, các doanh nghiệp đang bước vào cuộc đua khốc liệt để phát triển những chatbot có khả năng giao tiếp tự nhiên hơn, các trợ lý AI lập trình thông minh hơn và những hệ thống phân tích dữ liệu y tế với độ chính xác vượt trội. Điều này đồng nghĩa với việc phải huấn luyện các mô hình AI khổng lồ — điển hình như GPT-5 với quy mô có thể lên tới hàng nghìn tỷ tham số. Việc huấn luyện và vận hành các mô hình đồ sộ này đòi hỏi một năng lực tính toán cực kỳ lớn, và đó chính là lúc các nền tảng Cloud GPU phát huy vai trò then chốt.
Các nền tảng Cloud GPU đã trở thành lớp hạ tầng nền tảng cho mọi thứ, từ các mô hình AI đa phương thức cho đến những thế giới ảo sống động như thật. Chúng giúp loại bỏ hoàn toàn những thách thức về chi phí đầu tư và sự phức tạp trong việc quản lý phần cứng vật lý. Bài viết này sẽ so sánh tính năng, giá cả và năng lực của những nền tảng Cloud GPU hàng đầu hiện nay, giúp bạn lựa chọn được hạ tầng phù hợp nhất để hiện thực hóa những ý tưởng đột phá tiếp theo.
Nền tảng Cloud GPU là gì?
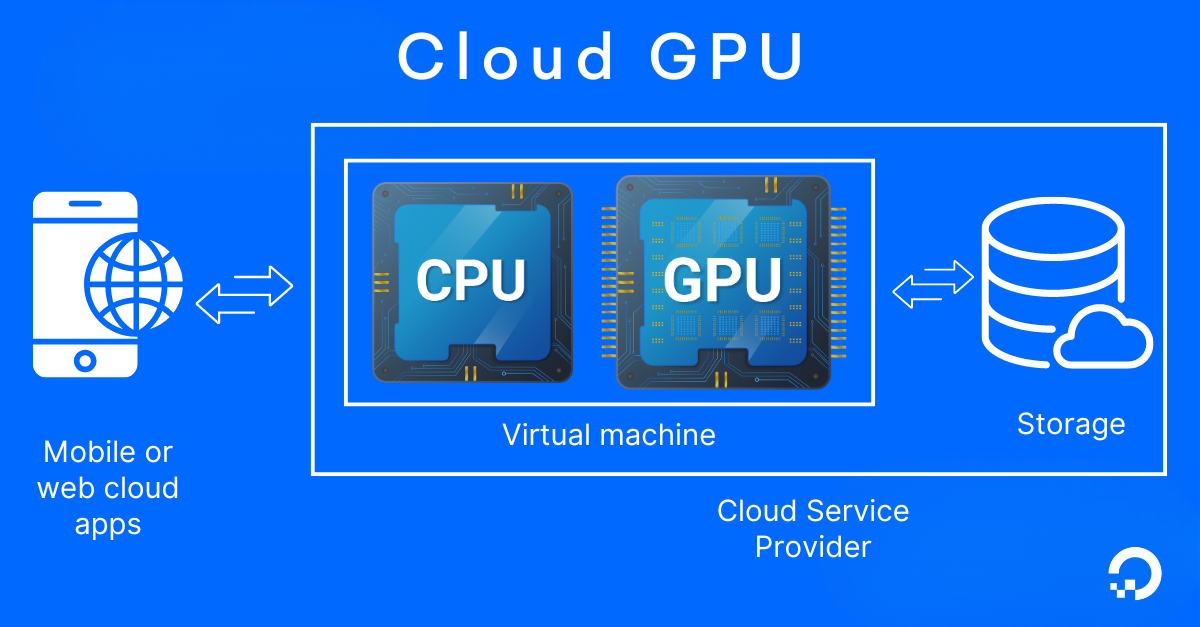
Nền tảng Cloud GPU là các dịch vụ hạ tầng dựa trên đám mây, cung cấp khả năng truy cập vào các bộ xử lý đồ họa (GPU) hiệu năng cao dành cho các tác vụ tính toán chuyên sâu. Các nền tảng này thực hiện ảo hóa các dòng GPU vật lý mạnh mẽ như NVIDIA A100, H100 hoặc L40S, sau đó cung cấp chúng thông qua các instances hoặc container. Nhờ đó, bạn có thể tăng tốc các tác vụ xử lý song song như học sâu, mô phỏng khoa học, render 3D và suy luận thời gian thực mà không cần trực tiếp quản lý hệ thống phần cứng tại chỗ.
Thông thường, bạn có thể tiếp cận các nguồn tài nguyên này theo hình thức thuê theo nhu cầu hoặc thông qua các reserved instances. Mô hình tính phí thường dựa trên số giờ sử dụng thực tế, các hợp đồng cam kết dài hạn, hoặc mô hình giá giao ngay – một giải pháp giúp tối ưu hóa chi phí cho các khối lượng công việc có tính linh hoạt cao.
TÌm hiểu thêm: Cloud GPU Là Gì? Lợi Ích và Ứng Dụng Thực Tế
💡Bạn đang thực hiện một dự án AI hoặc ML đột phá? DigitalOcean GPU Droplets cung cấp sức mạnh tính toán có thể mở rộng theo yêu cầu, hoàn hảo cho việc huấn luyện mô hình, xử lý các tập dữ liệu lớn và vận hành các neural networks phức tạp.
Liên hệ với đội ngũ CloudAZ ngay hôm nay để được tư vấn chuyên sâu về DigitalOcean GPU Droplets và các giải pháp phù hợp với nhu cầu của doanh nghiệp bạn!
Làm thế nào để lựa chọn nền tảng Cloud GPU phù hợp?
Việc lựa chọn một nền tảng Cloud GPU tối ưu phụ thuộc mật thiết vào yêu cầu của khối lượng công việc, mục tiêu hiệu suất, giới hạn ngân sách và phương thức vận hành của từng tổ chức. Từ kiến trúc GPU cho đến khả năng hỗ trợ điều phối, mỗi yếu tố đều đóng vai trò then chốt trong việc nâng cao hiệu suất tính toán và tối ưu hóa chi phí đầu tư.
Loại GPU và kiến trúc phần cứng
Việc lựa chọn đúng dòng GPU có tác động trực tiếp đến hiệu suất dự án. Chẳng hạn, các dòng GPU NVIDIA A100 hoặc H100 là những “cỗ máy” lý tưởng để huấn luyện các mô hình ngôn ngữ lớn (LLM), trong khi L40S hoặc RTX 6000 (Ada) lại chiếm ưu thế tuyệt đối trong các tác vụ suy luận với độ trễ thấp. Khi đánh giá, bạn cần lưu tâm đến băng thông bộ nhớ, hỗ trợ nhân Tensor và khả năng tính toán chính xác $FP16/INT8$ cho các tác vụ AI. Các thế hệ GPU mới không chỉ cải thiện tốc độ huấn luyện mà còn tối ưu hóa khả năng mở rộng và hiệu quả sử dụng năng lượng.
Khả năng cấu hình và mở rộng instances
Bạn nên ưu tiên các nền tảng hỗ trợ tùy chỉnh máy ảo (VM) hoặc container với số lượng GPU linh hoạt (từ một GPU đơn lẻ đến các cụm đa GPU). Nếu khối lượng công việc liên quan đến các tập dữ liệu khổng lồ hoặc yêu cầu song song hóa mô hình, khả năng tự động mở rộng và huấn luyện phân tán là những yếu tố không thể thiếu. Khả năng mở rộng chính là chìa khóa để duy trì các quy trình học sâu ổn định ở quy mô sản xuất.
Hiệu suất và thông lượng
Cần đánh giá kỹ các thông số kỹ thuật như TFLOPS, băng thông bộ nhớ và chuẩn kết nối PCIe/NVLink để xác định sức mạnh tính toán thực tế cũng như hiệu quả truyền tải dữ liệu của nền tảng Cloud GPU.
- NVIDIA H100: Cung cấp hiệu suất lên tới ~1.979 TFLOPS (FP16 Tensor Core) và băng thông bộ nhớ ~ 3,35 TB/s.
- NVIDIA A100: Đạt mức ~ 624 TFLOPS (FP16 Tensor Core) và băng thông ~ 2 TB/s.
Ngoài ra, việc đánh giá thông lượng trên các framework cụ thể như PyTorch hoặc TensorFlow cũng rất quan trọng. Những nền tảng tích hợp sẵn driver CUDA và hạ tầng mạng độ trễ thấp sẽ giúp rút ngắn đáng kể thời gian huấn luyện mô hình.
💡Bạn đang cảm thấy choáng ngợp trước các nhà cung cấp dịch vụ điện toán đám mây quy mô lớn? Hãy cùng tìm hiểu chi tiết bài so sánh của chúng tôi về AWS, Azure và GCP để hiểu rõ hơn sự khác biệt về chi phí, dịch vụ và hiệu năng giữa các ông lớn này, cũng như lý do tại sao việc khám phá các lựa chọn thay thế như DigitalOcean có thể là quyết định sáng suốt nhất của bạn.
Tích hợp lưu trữ và luồng dữ liệu
Tốc độ tải dữ liệu là yếu tố quyết định hiệu suất sử dụng GPU. Hãy lựa chọn các nền tảng cung cấp dịch vụ lưu trữ đối tượng thông lượng cao, lưu trữ khối độ trễ thấp và khả năng tích hợp mượt mà với các quy trình MLOps. Việc hỗ trợ lưu trữ đệm dữ liệu trên ổ cứng NVMe cục bộ sẽ giúp loại bỏ các điểm nghẽn I/O trong quá trình huấn luyện hoặc suy luận.
Khả năng điều phối và hỗ trợ Container
Để triển khai ở quy mô lớn, nền tảng Cloud GPU cần tương thích tốt với các công cụ điều phối đám mây phổ biến như Kubernetes hoặc Docker. Các giải pháp cung cấp container GPU được cấu hình sẵn (như mô hình 1-Click) giúp đơn giản hóa đáng kể quá trình thiết lập ban đầu. Ngoài ra, dịch vụ Managed Kubernetes với tính năng tự động mở rộng GPU sẽ hỗ trợ đắc lực cho các đội ngũ trong việc triển khai đồng thời nhiều tác vụ phức tạp.
Chi phí và tối ưu hóa ngân sách
Các nền tảng tính phí theo giờ mà không yêu cầu cam kết dài hạn rất phù hợp cho giai đoạn thử nghiệm hoặc các tác vụ tính toán tăng cường đột xuất. Ngược lại, các tùy chọn giá theo tháng sẽ giúp dự báo chi phí ổn định cho các nhu cầu sử dụng cố định.
Bạn nên tìm kiếm các đơn vị có chính sách giá minh bạch — bao gồm cả phí tính toán, GPU và băng thông trong một mức giá duy nhất — nhằm tránh các chi phí ẩn cho thư viện CUDA hoặc công cụ AI. Khi lập ngân sách, cần tính đến các chi phí bổ sung như lưu trữ khối, sao lưu (snapshot) và truyền tải dữ liệu ra ngoài, vì chúng sẽ tác động trực tiếp đến tổng chi phí sở hữu (TCO) trong môi trường vận hành thực tế.
Top 7 nền tảng Cloud GPU tốt nhất năm 2026
Các nền tảng Cloud GPU hiện đang được triển khai rộng rãi cho nhiều mục đích sử dụng đa dạng — từ truyền phát thực tế ảo (VR streaming) và lập bản đồ địa không gian quy mô lớn, cho đến dự báo thời tiết và mô hình hóa rủi ro tài chính. Bài viết đã tổng hợp danh sách bảy lựa chọn hàng đầu, bao gồm các dịch vụ thân thiện với nhà phát triển, các nền tảng suy luận (inference) chuyên dụng và các cụm GPU quy mô doanh nghiệp. Qua đó, bạn có thể dễ dàng tìm kiếm và đối chiếu hạ tầng phù hợp nhất với đặc thù khối lượng công việc của mình.
1. DigitalOcean Gradient™ AI GPU Droplets
DigitalOcean GPU Droplets là các máy chủ ảo hóa được trang bị GPU hiệu năng cao từ NVIDIA và AMD, cung cấp các cấu hình linh hoạt từ đơn GPU đến đa GPU. Những instances này được tích hợp sẵn lưu trữ NVMe cục bộ và các bộ hình ảnh tối ưu cho AI/ML, cho phép bạn khởi tạo môi trường tính toán với đầy đủ trình điều khiển và framework cài đặt sẵn chỉ trong vài cú nhấp chuột. Với dung lượng bộ nhớ GPU lớn, kết nối mạng tốc độ cao và tuân thủ các tiêu chuẩn khắt khe của doanh nghiệp, GPU Droplets hỗ trợ đa dạng khối lượng công việc—từ huấn luyện mô hình ngôn ngữ lớn (LLM) đến suy luận thời gian thực—trên hệ thống trung tâm dữ liệu toàn cầu.
Các tính năng chính:
- Phần cứng mạnh mẽ và đa dạng: Cung cấp dải phần cứng rộng lớn bao gồm NVIDIA H100, H200, L40S, RTX 4000/6000 Ada, cùng các dòng AMD Instinct MI300X hoặc MI325X. Bạn có thể lựa chọn từ cấu hình một GPU cho đến các hệ thống mạnh mẽ với 8 GPU.
- Môi trường sẵn sàng sử dụng: Cung cấp các hình ảnh Ubuntu dựng sẵn tích hợp trình điều khiển, bộ công cụ CUDA/ROCm và hỗ trợ container (như NVIDIA container toolkit cho Docker). Điều này giúp đơn giản hóa quy trình thiết lập môi trường và đảm bảo tính nhất quán trong triển khai.
- Hạ tầng và kết nối tối ưu: Mỗi máy chủ Cloud GPU Droplet bao gồm ổ đĩa NVMe kép (một ổ khởi động và một ổ tạm thời), kết hợp với băng thông mạng tốc độ cao (10 Gbps công cộng và 25 Gbps nội bộ), hỗ trợ triển khai trên nhiều khu vực địa lý khác nhau.
- Mô hình tính phí linh hoạt: Dịch vụ được tính phí theo từng giây với thời gian thuê tối thiểu chỉ 5 phút. Cơ chế này đảm bảo tính minh bạch về chi phí và độ tin cậy cao cho các khối lượng công việc trong môi trường vận hành thực tế.
2. AWS GPU
AWS cung cấp các môi trường tính toán tăng tốc bằng GPU nhằm hỗ trợ tối ưu cho các khối lượng công việc AI/ML và các tác vụ yêu cầu đồ họa cao. Nền tảng này mang đến các hình ảnh máy ảo cấu hình sẵn được tối ưu cho học sâu cùng các EC2 instances trang bị GPU đa dạng, đáp ứng mọi nhu cầu sử dụng thực tế.
Các tính năng chính:
- Deep Learning AMIs (DLAMIs): Các bộ hình ảnh DLAMI được cài đặt sẵn trình điều khiển GPU (như NVIDIA CUDA, cuDNN), các framework học sâu phổ biến (TensorFlow, PyTorch) và các thư viện giao tiếp (NCCL). Điều này giúp bạn triển khai nhanh chóng các khối lượng công việc trên nền tảng GPU thông qua nhiều dòng instances khác nhau.
- Các dòng EC2 instances đa dạng: EC2 cung cấp hai dòng GPU instances chính: Dòng P (như P5, P6) được tối ưu hóa cho huấn luyện chuyên sâu và các tác vụ tính toán hiệu năng cao (HPC); và Dòng G (bao gồm G4, G5, G6e) được thiết kế riêng cho các tác vụ render đồ họa, truyền phát video (streaming) và suy luận (inference).
- Kết nối tiên tiến cho khả năng mở rộng: Một số instances GPU nhất định, điển hình là các mẫu P4d, hỗ trợ huấn luyện phân tán với khả năng mở rộng cực cao nhờ các công nghệ như Elastic Fabric Adapter (EFA), GPUDirect RDMA và hạ tầng mạng độ trễ thấp 400 Gbps, đảm bảo hiệu suất giao tiếp vượt trội giữa các nút (nodes).
💡Bạn đang tìm kiếm giải pháp thay thế cho AWS? Với các sản phẩm của DigitalOcean, bạn có thể loại bỏ gánh nặng thiết lập cơ sở hạ tầng đám mây phức tạp.
-> Liên hệ với đội ngũ CloudAZ để nhận được tư vấn chuyên sâu về các giải pháp DigitalOcean
3. Google Cloud Platform (GCP) GPU
Google Cloud Compute Engine cho phép bạn tích hợp các dòng GPU NVIDIA mạnh mẽ như GB200, B200, H200, và nhiều dòng khác vào máy ảo để tối ưu hóa các tác vụ AI/ML. Nền tảng này cung cấp sự linh hoạt tối đa thông qua các dòng máy chuyên dụng đã được tối ưu hóa cho bộ tăng tốc (với GPU được gắn sẵn tự động) hoặc cho phép bạn tự gắn GPU vào các dòng máy đa năng N1 tùy theo nhu cầu cụ thể.
Các tính năng chính:
- Dòng máy tối ưu hóa cho bộ tăng tốc: Các dòng máy chuyên dụng như A4, A3, A2 và G2 được cấu hình sẵn với GPU đi kèm, giúp tối ưu hóa hiệu năng và đơn giản hóa quy trình cấp phát tài nguyên trong môi trường Compute Engine.
- Khả năng tùy chỉnh linh hoạt: Bạn có thể chủ động gắn các dòng GPU như T4, P4, P100 và V100 vào các instances máy ảo N1 đa năng. Cơ chế này tạo điều kiện thuận lợi cho việc điều chỉnh cấu hình chính xác theo đặc thù của từng khối lượng công việc.
- Hệ sinh thái triển khai mạnh mẽ: Các máy ảo hỗ trợ Cloud GPU của GCP có khả năng kết hợp mượt mà với các công cụ điều phối và quản lý hàng đầu như Vertex AI, Google Kubernetes Engine (GKE) và Slurm, giúp tối ưu hóa quy trình triển khai và vận hành.
4. Azure GPU
Microsoft Azure cung cấp hệ thống máy ảo (VM) tăng tốc bởi GPU, được phân loại thành hai dòng chính là N-series và NG-series. Hệ thống này được thiết kế để đáp ứng mọi nhu cầu tính toán khắt khe, từ huấn luyện mô hình AI cao cấp, tính toán hiệu năng cao (HPC) cho đến hạ tầng máy tính ảo (VDI) và chơi game trên đám mây. Trong đó, dòng máy ảo NC-series được trang bị các dòng GPU NVIDIA mạnh mẽ (như Tesla V100, K80), chuyên dùng để tối ưu hóa các khối lượng công việc tiêu tốn nhiều tài nguyên tính toán như học sâu, mô phỏng khoa học và render 3D.
Các tính năng chính:
- Khả năng mở rộng vượt trội với dòng ND-series: Khởi đầu từ các mẫu ND-series cơ bản (như Tesla P40), dòng sản phẩm này đã mở rộng lên đến các thế hệ ND A100 v4 và ND H100 v5. Mỗi instances đều cung cấp cấu hình đa GPU, kết hợp cùng sự hỗ trợ của công nghệ NVLink và InfiniBand, tạo điều kiện lý tưởng cho các tác vụ AI và HPC phân tán với tính liên kết chặt chẽ.
- Tối ưu hóa đồ họa với dòng NG-series: Dựa trên sức mạnh của GPU AMD Radeon PRO, các máy ảo dòng NG-series được thiết kế đặc thù để mang lại trải nghiệm mượt mà cho các tác vụ chơi game trên đám mây và vận hành máy tính ảo.
- Hạ tầng mạng và kết nối hiệu năng cao: Các biến thể thuộc dòng ND-series hỗ trợ khả năng mở rộng cụm (scale-out clusters) thông qua công nghệ GPU Direct RDMA và InfiniBand. Bên cạnh đó, kết nối NVLink giúp tăng cường tốc độ giao tiếp giữa các GPU, phục vụ đắc lực cho quy trình huấn luyện phân tán và các hệ thống HPC quy mô lớn.
5. CoreWeave

Các instances tính toán GPU của CoreWeave được thiết kế chuyên biệt để phục vụ việc huấn luyện mô hình AI, suy luận, tính toán hiệu năng cao (HPC) và các tác vụ render đồ họa. Nền tảng này được xây dựng dựa trên các kiến trúc NVIDIA tiên tiến nhất như H100, H200, A100, L40S, L40, GB200 NVL72 và phiên bản máy chủ RTX Pro 6000 Blackwell. Bạn có thể linh hoạt lựa chọn triển khai dưới dạng cấu hình HGX/HGX NVL hoặc các biến thể PCIe. Đáng chú ý, mỗi thiết lập GPU đều được kết hợp với bộ xử lý BlueField-3 DPU để giảm tải (offloading) các tác vụ mạng và lưu trữ cho hệ thống. Ngoài ra, CoreWeave còn hỗ trợ các cụm Cloud GPU đa nhân quy mô lớn với hạ tầng mạng InfiniBand và hệ thống điều phối Kubernetes trên nền tảng bare-metal.
Các tính năng chính:
- Hệ thống phần cứng hàng đầu: Cung cấp dải GPU rộng lớn từ GB200 NVL72 và H200 đến A100 và L40S, bao gồm cả phiên bản RTX Pro 6000 Blackwell dành cho các tác vụ suy luận với số lượng tham số khổng lồ, hỗ trợ đầy đủ cả cấu hình NVL/HGX và PCIe.
- Tối ưu hóa hiệu năng với DPU: Các tác vụ xử lý mạng và lưu trữ được chuyển giao cho các bộ xử lý BlueField-3 DPU đảm nhận, giúp giải phóng tài nguyên tính toán chính và tăng cường hiệu suất tổng thể.
- Kết nối cụm hiệu năng cao: Các cụm đa GPU được liên kết chặt chẽ thông qua hạ tầng mạng InfiniBand và các chuẩn kết nối thông lượng cao, giúp giảm thiểu tối đa độ trễ giao tiếp, tạo điều kiện lý tưởng cho quy trình huấn luyện phân tán.
6. Runpod
Runpod cung cấp dịch vụ tính toán GPU theo yêu cầu, cho phép bạn triển khai các hệ thống Cloud GPU tối ưu cho các khối lượng công việc AI, ML và HPC. Nền tảng này hỗ trợ đa dạng các hình thức từ GPU đám mây theo yêu cầu, các tác vụ serverless tự động mở rộng cho đến các cụm GPU đa nút. Đây là lựa chọn phù hợp cho các mục đích sử dụng như suy luận thời gian thực, tinh chỉnh mô hình, hệ thống dựa trên tác nhân và các tác vụ tính toán hạng nặng khác.
Các tính năng chính:
- GPU Serverless với khả năng mở rộng linh hoạt: Cung cấp tính năng tự động mở rộng từ mức không lên đến hàng nghìn worker. Đặc biệt, công nghệ FlashBoot giúp giảm thời gian khởi động nguội xuống dưới $200$ mili giây, đảm bảo hiệu suất phản hồi tức thì.
- Danh mục GPU NVIDIA phong phú: Runpod cung cấp dải sản phẩm GPU NVIDIA đa dạng bậc nhất, bao gồm các dòng: H200, B200, H100, A100, L40S, L40, A40, RTX 6000 Ada, RTX A6000, RTX 5090, RTX 4090, RTX 3090, L4 và RTX A5000.
- Tối ưu hóa luồng dữ liệu: Bạn có thể vận hành các quy trình dữ liệu (pipelines) với hệ thống lưu trữ tương thích S3, hoàn toàn không mất phí truyền tải dữ liệu vào/ra, đồng thời hỗ trợ nạp và xử lý dữ liệu quy mô lớn một cách hiệu quả.
- Mô hình tính phí linh hoạt: Hỗ trợ tính phí theo từng giây, giúp bạn tối ưu hóa ngân sách tối đa cho cả giai đoạn nghiên cứu lẫn triển khai thực tế.
7. Lambda
Lambda cung cấp hạ tầng Cloud GPU quy mô lớn được tối ưu hóa chuyên biệt cho huấn luyện AI, suy luận và nghiên cứu chuyên sâu. Nền tảng này sở hữu các kiến trúc NVIDIA mới nhất như các dòng GPU B200, H200 và H100 Tensor Core. Lambda hỗ trợ đa dạng mô hình triển khai, từ việc đặt trước đám mây riêng tư với quy mô hàng chục nghìn GPU cho đến các cụm GPU đa nút theo yêu cầu và cấu hình instances đơn lẻ. Những dòng GPU này được trang bị bộ nhớ HBM3e cùng các chuẩn kết nối tiên tiến, hỗ trợ đắc lực cho việc huấn luyện phân tán quy mô lớn và suy luận thông lượng cao đối với các mô hình ngôn ngữ lớn (LLM).
Các tính năng chính:
- Đám mây riêng tư cấp độ doanh nghiệp: Cung cấp quyền truy cập chuyên dụng vào các đội ngũ GPU khổng lồ (ví dụ: NVIDIA B300 và GB300) với hạ tầng mạng Quantum-2 InfiniBand tốc độ cao, đảm bảo hiệu suất truyền tải dữ liệu không điểm nghẽn.
- Cụm 1-Click Clusters™: Tính năng khởi tạo nhanh chóng các cụm đa nút NVIDIA B200 chỉ với một cú nhấp chuột, giúp các tổ chức ngay lập tức bắt tay vào huấn luyện các mô hình quy mô cực lớn mà không mất thời gian thiết lập hạ tầng phức tạp.
- Hệ sinh thái phần mềm Lambda Stack: Tích hợp sẵn PyTorch, TensorFlow, CUDA, cuDNN và các trình điều khiển NVIDIA mới nhất. Lambda Stack cung cấp quy trình cài đặt và nâng cấp được quản lý chặt chẽ, đảm bảo tính tương thích và ổn định tối đa cho môi trường phát triển.
- Hạ tầng mạng Blackwell thế hệ mới: Tận dụng tối đa sức mạnh của kiến trúc Blackwell Ultra, mang lại khả năng tính toán AI gấp nhiều lần so với thế hệ trước, đặc biệt hiệu quả cho các hệ thống Agentic AI và các mô hình suy luận phức tạp.
Tăng tốc dự án AI của bạn với DigitalOcean Gradient™ AI Droplets
Khai thác sức mạnh tối đa của GPU cho các dự án trí tuệ nhân tạo và học máy của bạn. DigitalOcean GPU Droplets cung cấp quyền truy cập theo yêu cầu vào các tài nguyên tính toán hiệu năng cao, cho phép các nhà phát triển, startup và những nhà đổi mới sáng tạo có thể huấn luyện mô hình, xử lý các tập dữ liệu khổng lồ và mở rộng quy mô dự án AI một cách linh hoạt. Giải pháp này giúp loại bỏ hoàn toàn sự phức tạp trong quản lý hạ tầng cũng như yêu cầu về các khoản đầu tư phần cứng ban đầu đắt đỏ.
Các tính năng chính:
- Cấu hình linh hoạt: bạn có thể tùy chọn từ các thiết lập đơn GPU cho đến hệ thống mạnh mẽ với 8 GPU, đáp ứng chính xác nhu cầu của từng giai đoạn dự án.
- Môi trường phần mềm tối ưu: Tích hợp sẵn ngôn ngữ lập trình Python và các gói phần mềm Học sâu phổ biến, giúp rút ngắn thời gian chuẩn bị và triển khai.
- Lưu trữ tốc độ cao: Mỗi instances đều bao gồm ổ đĩa khởi động (boot disk) và ổ đĩa tạm thời hiệu năng cao dựa trên công nghệ NVMe cục bộ, đảm bảo tốc độ truy xuất dữ liệu tối ưu.
Tìm hiểu thêm:
Hướng Dẫn Chọn GPU Droplet Tối Ưu Cho AI/ML
Serverless GPU DigitalOcean: Tối Ưu Hóa Tác Vụ Suy Luận Có Thể Mở Rộng
Hãy đăng ký ngay hôm nay để khai phá những tiềm năng vô hạn của Cloud GPU Droplets. Đối với các nhu cầu về giải pháp tùy chỉnh, phân bổ GPU quy mô lớn hoặc reserved instances, hãy liên hệ với đội ngũ kinh doanh của CloudAZ để tìm hiểu cách DigitalOcean tiếp sức cho những khối lượng công việc AI/ML khắt khe nhất của bạn!









