Suy luận (inference) cho LLM ở môi trường production không chỉ dừng lại ở việc sở hữu GPU mạnh. Điều cốt lõi nằm ở khả năng tối ưu hóa sâu toàn bộ serving stack — từ kỹ thuật lượng tử hóa (quantization), attention kernels, quản lý bộ nhớ, cho đến chiến lược song song hóa (parallelism). Thực tế cho thấy, nhiều đội ngũ triển khai các mô hình như Llama 3.3 70B trên cấu hình mặc định đang vô tình bỏ phí phần lớn năng lực phần cứng: FLOPs không được khai thác tối đa, băng thông bộ nhớ bị lãng phí, và GPU tiêu tốn hàng giờ chờ đợi thay vì thực thi tính toán.
Nhằm giải quyết bài toán này, DigitalOcean đã xây dựng Inference Optimized Image — một hệ điều hành được cấu hình sẵn, tích hợp trực tiếp trên nền tảng GPU Droplets. Image này kết hợp đồng bộ nhiều lớp tối ưu quan trọng như speculative decoding, lượng tử hóa FP8, FlashAttention-3, paged attention, tối ưu hóa xử lý đồng thời (concurrency optimization) và cơ chế prompt caching, tất cả trong một gói triển khai duy nhất.
Kết quả thử nghiệm nội bộ cho thấy những cải thiện đáng kể:
- Throughput tăng 143% (2.000 so với 823 tokens/giây)
- TTFT giảm 40,7% (187,9ms so với 316,83ms)
- Chi phí trên mỗi triệu tokens giảm 75% (1,472 USD so với 5,80 USD)
Đáng chú ý, các kết quả này đạt được khi vận hành Llama 3.3 70B trên 2 GPU H100 thay vì 4, cho thấy hiệu suất phần cứng được khai thác hiệu quả hơn đáng kể.
Bài viết phân tích chi tiết từng lớp tối ưu trong stack, lý do kỹ thuật phía sau mỗi quyết định thiết kế, cũng như phương pháp benchmark và kết quả kiểm thử chứng minh những cải thiện vượt trội này.
Prefill, Decode và Tính Nhân Lên Của Tối Ưu Hóa
Như đã phân tích trong bài viết về benchmarking LLM inference, quá trình suy luận vận hành qua hai pha riêng biệt với đặc tính tính toán khác nhau về bản chất: prefill và decode.
- Prefill phase xử lý toàn bộ prompt đầu vào thông qua forward pass của mô hình — bao gồm self-attention, layer normalization và feed-forward network. Đây là pha compute-bound, với cường độ số học cao (FLOPs trên mỗi byte truyền tải).
- Decode phase sinh token theo từng bước một. Ở mỗi token, toàn bộ weight matrix và KV cache phải được nạp từ HBM, khiến pha này trở thành memory-bandwidth-bound thuần túy.
Sự khác biệt này có ý nghĩa chiến lược: mỗi lớp tối ưu trong stack nhắm vào một “nút thắt cổ chai” riêng biệt. Speculative decoding giải quyết tính tuần tự của decode; FP8 quantization giảm footprint bộ nhớ và tăng tốc tính toán qua Tensor Cores; FlashAttention-3 tối ưu pha attention nặng prefill; paged attention cải thiện hiệu suất bộ nhớ dưới tải đồng thời. Do các tối ưu này xử lý các bottleneck trực giao, hiệu quả đạt được mang tính nhân lên (multiplicative) — mỗi lớp khuếch đại lợi ích của lớp còn lại trong toàn bộ pipeline suy luận.
Optimization Stack
Speculative Decoding
Sinh văn bản autoregressive truyền thống mang tính tuần tự tuyệt đối: mỗi token yêu cầu một forward pass đầy đủ qua mô hình 70B. Ở pha decode, forward pass này bị chi phối bởi băng thông bộ nhớ — GPU dành nhiều thời gian di chuyển weight từ HBM sang compute cores hơn là thực hiện phép nhân ma trận.
Speculative decoding phá vỡ mô hình tuần tự này bằng cách sử dụng một draft model nhỏ và nhanh để đề xuất nhiều token ứng viên song song. Mô hình đích 70B sau đó xác thực các token này trong một forward pass duy nhất. Do chi phí xác thực N token xấp xỉ chi phí sinh 1 token, mỗi lần dự đoán được chấp nhận sẽ tạo ra nhiều token với chi phí tính toán của một.
Thách thức kỹ thuật nằm ở việc chọn draft model:
- Phải đủ nhanh để overhead không triệt tiêu lợi ích.
- Phải đủ chính xác để tỷ lệ chấp nhận cao.
Cặp draft–target được tinh chỉnh riêng cho kiến trúc Llama 3.3 70B, tối ưu hóa acceptance rate trên các phân phối workload benchmark. Đây là thành phần đóng góp lớn nhất vào mức tăng throughput và giảm TTFT trong toàn bộ stack.
FP8 Quantization
Vận hành Llama 3.3 70B ở chuẩn FP16 yêu cầu khoảng 140GB bộ nhớ GPU chỉ cho weights — gần bằng hai GPU H100 HBM3 trước khi cấp phát KV cache hay activation. Vì vậy, triển khai thông thường cần đến 4 H100.
FP8 quantization giảm một nửa footprint bộ nhớ bằng cách biểu diễn weights dưới dạng số thực dấu chấm động 8-bit (E4M3), nén mô hình xuống khoảng 70GB, cho phép phục vụ trên cấu hình 2 H100 với TP=2.
Lợi ích không chỉ nằm ở bộ nhớ. Tensor Cores FP8 trên H100 đạt đỉnh hiệu năng 1.979 TFLOPS, gấp đôi FP16 (989 TFLOPS). Nghĩa là:
- Không chỉ giảm số GPU cần thiết.
- Mỗi GPU cũng xử lý nhanh hơn trong mỗi forward pass.
Kết quả thực tiễn: cấu hình 2×H100 trở thành nền tảng cho mức giảm chi phí 75% — một nửa số GPU, mỗi GPU lại chạy nhanh hơn.
FlashAttention-3 và Paged Attention
Chi phí attention tăng theo bậc hai theo độ dài chuỗi, trở thành bottleneck lớn cho prompt và generation dài.
FlashAttention-3
FlashAttention-3 tái cấu trúc phép tính attention nhằm giảm thiểu thao tác đọc/ghi HBM. Thay vì materialize toàn bộ ma trận attention N×N trong bộ nhớ GPU, thuật toán chia nhỏ (tiling) để tính toán và tiêu thụ attention score trực tiếp trong SRAM (bộ nhớ on-chip tốc độ cao), không bao giờ ghi toàn bộ ma trận ra HBM.
Trên GPU H100, thuật toán còn khai thác TMA (Tensor Memory Accelerator) — đặc trưng của kiến trúc Hopper — để chồng lấp truyền dữ liệu với tính toán, nâng cao hiệu suất pipeline.
Paged Attention
Paged attention giải quyết bài toán quản lý KV cache.
Trong cấu hình truyền thống, KV cache được cấp phát liên tục theo từng request, dẫn đến phân mảnh bộ nhớ: chuỗi ngắn giữ vùng bộ nhớ dự trữ mà chuỗi dài cần dùng.
Paged attention áp dụng khái niệm bộ nhớ ảo của hệ điều hành: KV cache được quản lý theo block kích thước cố định và cấp phát theo nhu cầu. Điều này cải thiện đáng kể mức sử dụng bộ nhớ trong môi trường concurrent với độ dài chuỗi biến thiên.
Kết hợp lại, hai tối ưu này cho phép phục vụ nhiều request đồng thời hơn trong cùng giới hạn bộ nhớ, giữ throughput cao và TTFT ổn định khi concurrency tăng từ 1 lên 16 người dùng.
Concurrent Optimization
Đây là lớp tối ưu ít trực quan nhất nhưng mang lại cải thiện đáng kể cho môi trường đa mô hình.
Concurrent optimization nghĩa là chạy nhiều instance của cùng một mô hình song song trên cùng phần cứng, thay vì một instance chiếm toàn bộ GPU (cách tiếp cận phổ biến của vLLM).
Cơ sở của chiến lược này nằm ở mô hình sử dụng GPU:
- Một mô hình 70B chia trên 8 GPU với TP=8 thường không bão hòa hoàn toàn băng thông bộ nhớ do overhead giao tiếp liên GPU.
- Các phép all_reduce và all_gather gây latency, làm compute unit bị nhàn rỗi.
Khi chạy 4 instance song song với TP=2:
- Mỗi cặp GPU hoạt động độc lập.
- Băng thông được khai thác hiệu quả hơn.
- Đồng thời tạo 4 pipeline xử lý batch riêng biệt, loại bỏ bottleneck tuần tự hóa.
Kết quả đo lường trên hệ thống 8×H100:
| Model | Single Instance (tok/s) | 4 Concurrent (tok/s) | Mức cải thiện |
| Llama 3.1 8B | 59.941 | 101.804 | +69,8% |
| Llama 3.3 70B | 11.927 | 22.948 | +92,4% |
| DeepSeek-R1-Distill 70B | 12.202 | 23.348 | +91,3% |
Các cải thiện này chủ yếu đến từ việc khai thác phần cứng hiệu quả hơn — không thay đổi mô hình, không bổ sung GPU, chỉ phân bổ tài nguyên thông minh hơn trên cùng nền silicon.
Prompt Caching
Trong các ứng dụng thực tế, người dùng thường gửi những prompt có mức độ trùng lặp cao — bao gồm system prompt, few-shot examples hoặc ngữ cảnh tài liệu dùng chung. Việc tính toán lại KV cache cho các token tiền tố (prefix) giống hệt nhau thực chất là lãng phí tài nguyên.
Prompt caching giải quyết vấn đề này bằng cách lưu trữ và tái sử dụng KV cache của các prefix đã được xử lý trước đó. Khi một request mới chia sẻ cùng prefix, hệ thống bỏ qua bước prefill tương ứng, loại bỏ hoàn toàn phần tính toán dư thừa.
Trong workload production, 50–80% nội dung prompt thường là ngữ cảnh chung (system instructions, tool definitions, tài liệu tham chiếu). Prompt caching khiến các token dùng chung này gần như “miễn phí” ở các request tiếp theo. Kết quả là:
- Giảm TTFT tỷ lệ thuận với mức độ overlap.
- Giảm chi phí compute trên mỗi request, đặc biệt rõ rệt trong hệ thống có lưu lượng truy cập lặp lại cao.
Về bản chất, đây là một tối ưu tập trung vào pha prefill và mang lại hiệu quả trực tiếp trong các môi trường multi-user hoặc agentic workflow.
Benchmark Methodology
Để đánh giá Inference Optimized Image, nhóm triển khai so sánh với một baseline không tối ưu (vanilla configuration) trong ba kịch bản sử dụng thực tế, mỗi kịch bản được thiết kế nhằm gây áp lực lên các thành phần khác nhau của pipeline suy luận:
| Scenario | Input Tokens | Output Tokens | Use Case |
| Standard Chat | 512 | 512 | Conversational AI, chatbot |
| Summarization | 1.024 | 512 | Tóm tắt tài liệu, trích xuất thông tin |
| Long-form Generation | 2.048 | 1.024 | Sáng tạo nội dung, phân tích chuyên sâu |
Mỗi kịch bản được kiểm thử ở các mức độ concurrency: 1, 2, 4, 8 và 16 người dùng đồng thời.
Toàn bộ benchmark sử dụng Llama 3.3 70B làm target model, với backend phục vụ là vLLM.
Cấu hình triển khai:
- Optimized configuration: 2×H100 GPU (TP=2), áp dụng toàn bộ stack tối ưu.
- Baseline configuration: 4×H100 GPU (TP=4), không áp dụng bất kỳ tối ưu nào.
Các số liệu được báo cáo là giá trị trung bình trên toàn bộ kịch bản và mức concurrency, đảm bảo phản ánh chính xác hiệu suất tổng thể thay vì chỉ một workload đơn lẻ.
Cách tiếp cận benchmark này cho phép đánh giá toàn diện tác động của từng lớp tối ưu — từ compute-bound (prefill), memory-bound (decode), đến khả năng mở rộng khi concurrency tăng cao.
Kết quả kiểm tra
Throughput: Tăng 143% So Với Baseline
Cấu hình tối ưu đạt 2.000 tokens/giây trên 2×H100 GPU, trong khi baseline chỉ đạt 823 tokens/giây trên 4×H100 GPU.
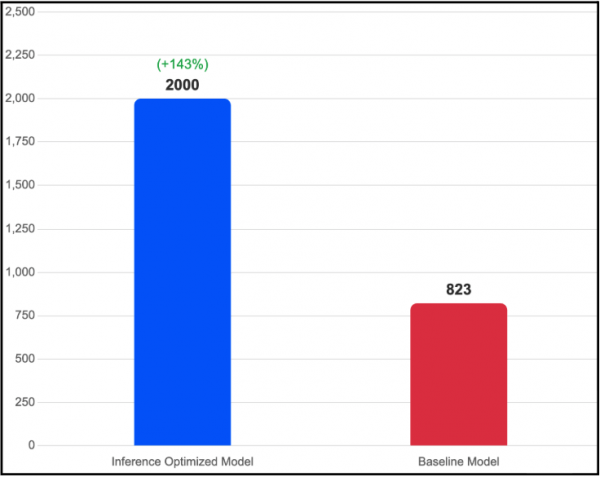
Hình 1: So sánh throughput đầu ra giữa Inference Optimized Image (2×H100, TP=2) và Baseline (4×H100, TP=4). Cấu hình tối ưu đạt throughput cao hơn 143% dù chỉ sử dụng một nửa tài nguyên GPU.
Điểm đáng chú ý ở đây không chỉ là hiệu suất cao hơn trên mỗi GPU — mà là hiệu suất tuyệt đối vượt trội trong khi dùng ít phần cứng hơn.
Kết quả này đến từ hiệu ứng cộng hưởng của nhiều lớp tối ưu:
- Speculative decoding: sinh nhiều token hơn trong mỗi forward pass.
- FP8 quantization: tăng tốc forward pass nhờ Tensor Cores FP8 trên H100.
- TP=2 thay vì TP=4: giảm overhead giao tiếp liên GPU (ít đồng bộ hóa inter-GPU hơn).
Toàn bộ các yếu tố trên kết hợp lại tạo ra mức tăng trưởng hiệu suất mang tính nhân lên.
Cũng cần lưu ý rằng lợi thế throughput rõ rệt nhất ở các mức concurrency thấp đến trung bình. Như đã phân tích trong phương pháp benchmark, luôn tồn tại một điểm cân bằng Pareto giữa throughput và concurrency. Ở mức concurrency rất cao (32+), giới hạn bộ nhớ của cấu hình TP=2 bắt đầu ảnh hưởng đến mức cải thiện.
Tuy nhiên, với phần lớn workload production vận hành trong dải concurrency từ 1–16 người dùng đồng thời, mức tăng 143% throughput vẫn được duy trì ổn định khi chạy Llama 3.3 70B trên hạ tầng sử dụng GPU NVIDIA H100.
Time-to-First-Token: Giảm 40,7% So Với Baseline
Cấu hình tối ưu đạt TTFT 187,9ms, trong khi baseline ghi nhận 316,83ms.
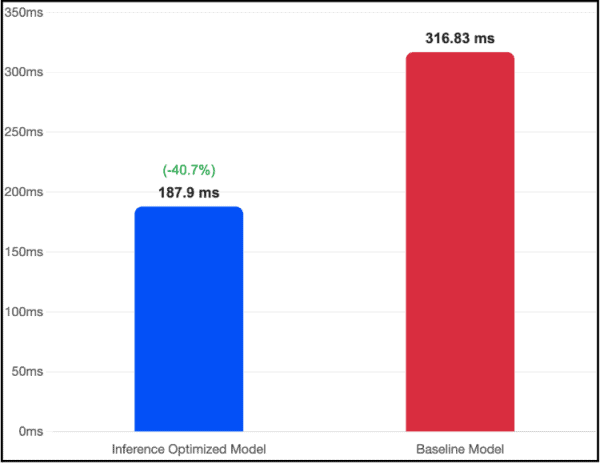
Hình 2: So sánh Time-to-First-Token giữa Inference Optimized Image và Baseline. Với 187,9ms, cấu hình tối ưu nằm dưới ngưỡng 200ms — mốc thường được xem là “phản hồi tức thì” trong các ứng dụng tương tác.
Đối với các hệ thống tương tác như chatbot, coding assistant hay real-time AI agents, TTFT là chỉ số người dùng cảm nhận trực tiếp. Dù throughput tổng thể có cao đến đâu, nếu token đầu tiên xuất hiện chậm, trải nghiệm vẫn bị đánh giá là thiếu mượt mà.
Mức cải thiện 40,7% này đến chủ yếu từ hai thành phần:
- Speculative decoding: draft model nhỏ sinh token đầu tiên nhanh hơn so với việc chờ full forward pass của mô hình 70B.
- FlashAttention-3: tăng tốc pha prefill, rút ngắn thời gian xử lý prompt đầu vào.
Khi vận hành Llama 3.3 70B trên GPU NVIDIA H100, cấu hình tối ưu duy trì TTFT dưới ngưỡng 200ms — một mốc mà nhiều nghiên cứu UX xác định là ranh giới giữa “phản hồi tức thì” và “có độ trễ nhận thấy”.
Trong bối cảnh production, điều này không chỉ là cải thiện kỹ thuật, mà là cải thiện trực tiếp trải nghiệm người dùng cuối.
Cost Efficiency: Giảm 75% So Với Baseline
Cấu hình tối ưu đạt chi phí 1,472 USD cho mỗi triệu tokens, trong khi baseline ở mức 5,80 USD cho mỗi triệu tokens.
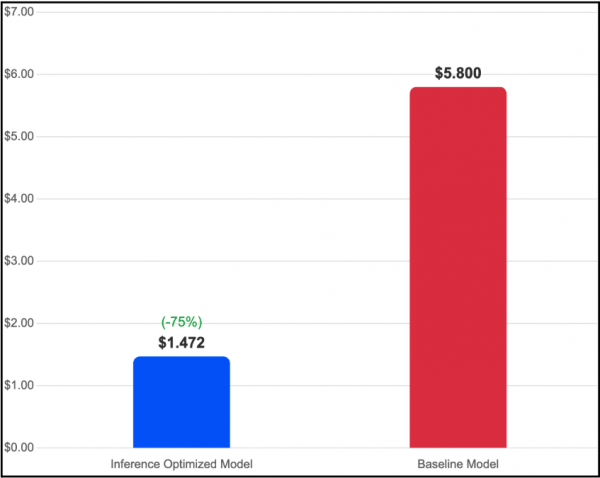
Hình 3: So sánh hiệu quả chi phí (USD trên mỗi triệu tokens). Inference Optimized Image giảm 75% chi phí trên mỗi token nhờ kết hợp giữa việc giảm một nửa số GPU và tăng throughput trên mỗi GPU.
Mức giảm chi phí này mang tính nhân lên (multiplicative):
- Chạy trên 2×H100 thay vì 4×H100 → chi phí hạ tầng theo giờ giảm ngay 50%.
- Throughput tăng 143% → mỗi đô la chi cho GPU tạo ra nhiều token hơn đáng kể.
Hai yếu tố này kết hợp lại khiến chi phí trên mỗi token giảm tổng cộng 75%.
Trong thực tế vận hành, một workload tiêu tốn 10.000 USD/tháng trên cấu hình vanilla có thể giảm xuống khoảng 2.500 USD/tháng khi chạy trên cấu hình tối ưu — đồng thời cải thiện cả latency và throughput (kết quả thực tế phụ thuộc vào chi tiết triển khai production).
Cấu hình này được benchmark với Llama 3.3 70B trên GPU NVIDIA H100.
Throughput vs. Concurrency
Các số liệu tổng hợp ở trên chỉ phản ánh một phần bức tranh. Phân tích theo từng mức concurrency cho thấy cách cấu hình tối ưu mở rộng dưới tải tăng dần.
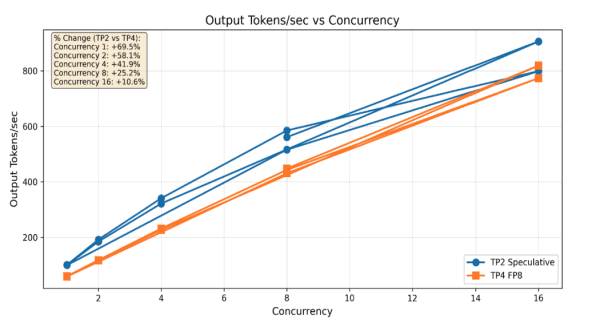
Hình 4: So sánh tokens/giây theo mức concurrency (1–16) giữa cấu hình tối ưu (TP=2, speculative decoding) và baseline (TP=4, FP8-only).
Kết quả:
- Concurrency 1: +69,5%
- Concurrency 2: +59,1%
- Concurrency 4: +41,8%
- Concurrency 8: +25,3%
- Concurrency 16: +10,6%
Lợi thế lớn nhất xuất hiện ở mức concurrency thấp đến trung bình. Khi concurrency tăng cao, đường hiệu suất bắt đầu hội tụ. Nguyên nhân là giới hạn bộ nhớ của cấu hình TP=2: ở mức tải cực cao, dung lượng KV cache lớn hơn trong cấu hình TP=4 bắt đầu thu hẹp khoảng cách.
Điều này phản ánh đặc tính tự nhiên của bài toán: tối ưu compute và giao tiếp GPU mang lại lợi ích lớn ở vùng tải phổ biến, nhưng memory envelope vẫn là ràng buộc vật lý khi mở rộng cực hạn.
Cost per Million Tokens vs. Concurrency
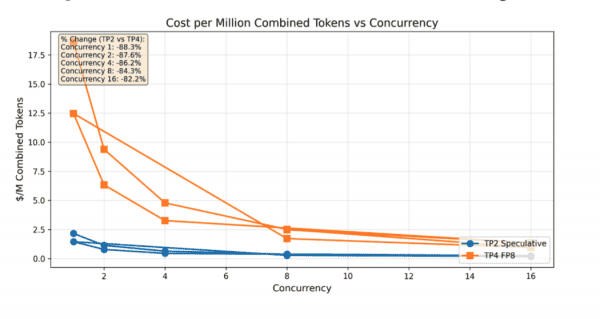
Hình 5: So sánh chi phí trên mỗi triệu tokens theo mức concurrency.
Cấu hình tối ưu duy trì lợi thế chi phí ở mọi mức concurrency được kiểm thử:
- Concurrency 1: giảm hơn 88%
- Concurrency 16: vẫn giảm trên 42%
Biểu đồ này đặc biệt quan trọng cho capacity planning. Phần lớn workload production không duy trì concurrency 16+ liên tục; chúng thường hoạt động trong khoảng 1–8 với các đợt tăng đột biến ngắn hạn. Chính trong “sweet spot” này, Inference Optimized Image phát huy lợi thế chi phí trên mỗi token mạnh nhất.
Từ 4 GPU Xuống 2 GPU: Câu Chuyện Về Hiệu Quả Hạ Tầng
Một trong những kết quả thuyết phục nhất của quá trình tối ưu này nằm ở tác động đến quy hoạch hạ tầng.
Trước đây, vận hành Llama 3.3 70B ở môi trường production gần như mặc định yêu cầu tối thiểu 4 GPU H100. Ở chuẩn FP16, mô hình đơn giản là không thể “fit” trên ít hơn số GPU này nếu vẫn muốn dành đủ bộ nhớ cho KV cache và batching đồng thời.
Inference Optimized Image thay đổi căn bản phương trình đó:
- FP8 quantization nén mô hình để vừa trong cấu hình 2×H100.
- Speculative decoding và FlashAttention-3 đảm bảo cấu hình 2 GPU không chỉ “chạy được” mà còn vượt hiệu năng cấu hình 4 GPU không tối ưu.
- Paged attention quản lý KV cache hiệu quả ở mức concurrency cao, giúp deployment 2 GPU không bị nghẽn khi chịu tải production.
Hệ quả dây chuyền đối với kinh tế hạ tầng là đáng kể:
- Ít GPU node hơn.
- Giảm overhead giao tiếp liên GPU (NVLink giữa 2 GPU đơn giản hơn so với mesh 4 GPU).
- Giảm tiêu thụ điện năng.
- Giảm độ phức tạp vận hành.
Mức giảm 75% chi phí trên mỗi token phản ánh phần tiết kiệm compute trực tiếp. Tuy nhiên, nếu tính thêm các hiệu ứng bậc hai như điện năng, làm mát, vận hành và độ phức tạp hệ thống, tổng chi phí sở hữu (TCO) có thể còn cải thiện nhiều hơn.
Linh Hoạt Trên Nhiều Tầng GPU
Dù các benchmark nổi bật tập trung vào NVIDIA H100, Inference Optimized Image cũng hỗ trợ:
- NVIDIA L40S
- NVIDIA RTX 6000 Ada
- NVIDIA RTX 4000 Ada
Stack tối ưu được áp dụng xuyên suốt các kiến trúc GPU khác nhau, mở rộng khả năng inference production từ cấu hình H100 hiệu năng tối đa đến L40S tối ưu chi phí cho các deployment ngân sách hạn chế.
Điều Này Có Ý Nghĩa Gì Cho Inference Ở Quy Mô Lớn?
Quá trình xây dựng và benchmark image tối ưu này cho thấy một số xu hướng quan trọng, vượt ra ngoài một mô hình hay cấu hình phần cứng cụ thể.
Tối ưu hóa mang tính nhân lên, không phải cộng dồn
Mức tăng 143% throughput không đến từ một kỹ thuật đơn lẻ. Nó là kết quả của:
- Speculative decoding
- FP8 quantization
- FlashAttention-3
- Paged attention
- Concurrent optimization
- Prompt caching
Mỗi lớp xử lý một bottleneck trực giao trong pipeline. Chỉ tối ưu một lớp sẽ khai thác được một phần nhỏ tiềm năng hiệu năng. Toàn bộ stack mới tạo ra khác biệt thực sự.
Hiệu quả phần cứng là bài toán phần mềm
Cùng một cụm NVIDIA H100 có thể cho hiệu năng rất khác nhau tùy cấu hình. Benchmark cho thấy các cấu hình mặc định chỉ khai thác một phần công suất throughput khả dụng.
Inference Optimized Image thu hẹp khoảng cách đó hoàn toàn bằng phần mềm — không silicon tùy chỉnh, không thay đổi phần cứng, chỉ là tinh chỉnh serving stack một cách có hệ thống. Việc hiểu rõ “giới hạn tốc độ ánh sáng” (speed-of-light frontier) của phần cứng cụ thể là bước đầu tiên trong chiến lược tối ưu.
Ít GPU hơn có thể mang lại hiệu năng cao hơn
Chạy Llama 3.3 70B trên 2 GPU (TP=2) với speculative decoding vượt qua cấu hình 4 GPU (TP=4) không tối ưu.
Nguyên nhân:
- TP=4 làm tăng overhead all_reduce và giao tiếp liên GPU.
- Không có speculative decoding, mỗi forward pass vẫn chỉ sinh một token, bất kể số GPU.
Mở rộng thô (brute-force scaling) không thay thế được tối ưu thông minh. Inference hiệu quả thắng thế trước scaling đơn thuần.
Image tối ưu sẵn hạ thấp rào cản production
Phần lớn đội ngũ không có chuyên môn sâu về GPU systems engineering để:
- Tinh chỉnh cấu hình vLLM
- Chọn draft model phù hợp
- Hiệu chỉnh FP8 quantization
- Cấu hình paged attention đúng cách
Inference Optimized Image đóng gói nhiều tháng tinh chỉnh thành một deployment sẵn sàng production trong vài phút. Điều này cho phép các đội tập trung vào xây dựng ứng dụng thay vì trở thành chuyên gia hạ tầng GPU.
Inference Optimized Image dành cho GPU Droplets hiện khả dụng trên các tầng H100, L40S, RTX 6000 Ada và RTX 4000 Ada. Dù bạn vận hành một mô hình cho conversational AI hay triển khai nhiều mô hình đồng thời trong hệ thống multi-agent, cấu hình tối ưu cung cấp hiệu năng production-grade ngay từ khi khởi tạo.
Tìm hiểu thêm:
Mở rộng Agentic Inference Cloud với GPU AMD Instinct™ MI350X
Moltbook là gì? Mạng xã hội dành cho AI Agents trong năm 2026
Liên hệ với CloudAZ ngay hôm nay để được tư vấn nhận $200 Credit dành cho các dịch vụ DigitalOcean ngay hôm nay!









