Tinh chỉnh các mô hình ngôn ngữ lớn (Fine-tuning LLMs) là nơi giao thoa giữa thử nghiệm và ứng dụng thực tế. Đây là khoảnh khắc bạn có thể “dạy” một mô hình hiểu rõ kiến thức chuyên ngành của công ty, tinh chỉnh nó cho các trường hợp sử dụng cụ thể, hoặc thậm chí điều chỉnh giọng văn và định dạng phản hồi để phù hợp hơn với đối tượng của bạn.
Tuy nhiên, tất cả những điều kỳ diệu này không thể xảy ra nếu thiếu phần cứng phù hợp. Lựa chọn GPU chính xác sẽ giúp tăng tốc quá trình đào tạo, kích hoạt các chế độ độ chính xác cao cấp và đơn giản hóa việc mở rộng trên các tập dữ liệu. Dù bạn đang thử nghiệm một mô hình 7 tỷ tham số (như Phi-4-mini-instruct) trên một GPU dành cho game thủ trong máy trạm cá nhân hay điều phối các cụm đa GPU trên đám mây, việc lựa chọn thông minh sẽ giúp bạn xây dựng quy trình làm việc hiệu quả và năng suất. Trong bài viết này, chúng ta sẽ cùng tìm hiểu về các tùy chọn GPU cho việc tinh chỉnh, những ưu và nhược điểm của chúng, và cách lựa chọn GPU phù hợp với mục tiêu phát triển của bạn.
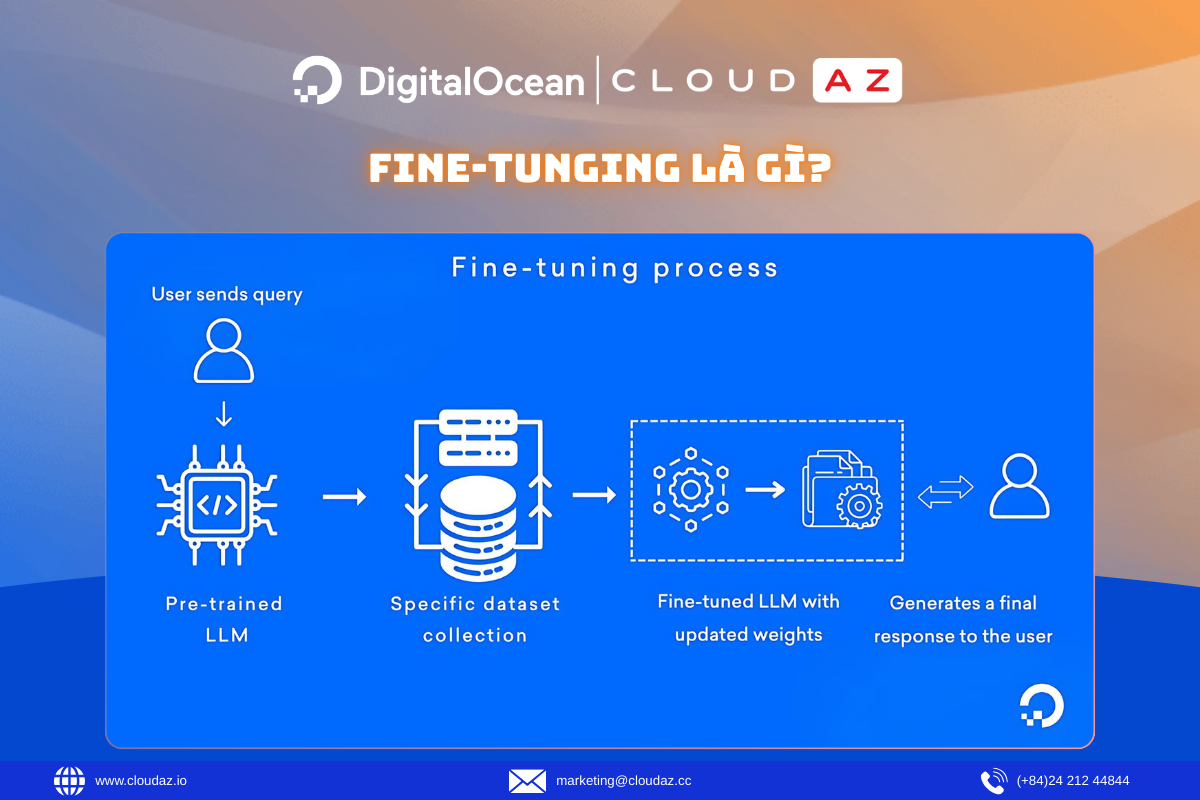
Fine-tuning là gì?
Fine-tuning (tinh chỉnh) là quá trình bạn lấy một mô hình đã được đào tạo sẵn, ví dụ như mô hình ngôn ngữ lớn (LLM) hoặc mô hình thị giác máy tính, sau đó điều chỉnh để nó phù hợp với một nhiệm vụ, tập dữ liệu hoặc lĩnh vực cụ thể.
Thay vì phải đào tạo lại từ đầu, tinh chỉnh cho phép tận dụng kiến thức sẵn có của mô hình và cập nhật các trọng số của nó với dữ liệu mới. Quá trình này giúp mô hình trở nên chính xác và hiệu quả hơn cho các ứng dụng chuyên biệt, như phân tích cảm xúc, xử lý hình ảnh y tế trong lĩnh vực chăm sóc sức khỏe, hay xây dựng các chatbot hỗ trợ khách hàng.
Vì sao lựa chọn GPU lại quan trọng đối với việc tinh chỉnh?
Việc thiết lập GPU phù hợp đóng vai trò then chốt trong quá trình tinh chỉnh các mô hình ngôn ngữ lớn (LLM) và mạng thần kinh, bởi vì đây là một quy trình đòi hỏi rất nhiều bộ nhớ và sức mạnh tính toán. Quyết định lựa chọn GPU của bạn sẽ ảnh hưởng trực tiếp đến hiệu suất, tính khả thi, chi phí và khả năng mở rộng của toàn bộ quy trình đào tạo.
| Miêu tả | Ví dụ | |
| Dung lượng bộ nhớ (VRAM) | Xác định kích thước mô hình tối đa có thể vừa với bộ nhớ GPU. | Mẫu 13B có thể cần hơn 200 GB VRAM để tinh chỉnh hoàn toàn và yêu cầu đa GPU A100/H100. Với QLoRA, cùng mẫu này có thể chạy trên RTX 4090 24 GB. |
| Sức mạnh tính toán | Số lượng lõi CUDA , lõi Tensor và tần số xung nhịp của GPU ảnh hưởng đến tốc độ thực hiện phép nhân ma trận và cập nhật gradient. | H100 có thể đào tạo nhanh hơn A100 tới 4 lần khi sử dụng độ chính xác FP8. |
| Băng thông kết nối | Ảnh hưởng đến tốc độ đồng bộ hóa trong đào tạo đa GPU phân tán. | Tám GPU A100 với NVLink đồng bộ nhanh hơn so với các GPU tương tự giao tiếp qua PCIe. |
| Tối ưu hóa | Ảnh hưởng đến sự đánh đổi giữa hiệu quả và độ chính xác (FP32, FP16, BF16, FP8). | Đào tạo trong BF16 sử dụng ~½ bộ nhớ của FP32, trong khi FP8 trên H100s tiết kiệm được nhiều hơn nữa. |
Đọc thêm: Hướng Dẫn Chọn GPU Droplet Tối Ưu cho AI/ML 2025
Cách lựa chọn GPU phù hợp để tinh chỉnh các mô hình lớn?
Để chọn được cấu hình GPU hoàn hảo cho việc tinh chỉnh mô hình lớn, bạn cần đánh giá kích thước của mô hình, phương pháp tinh chỉnh dự định sử dụng, và cơ sở hạ tầng bạn có. Các bước dưới đây sẽ giúp bạn kết hợp phần cứng, kỹ thuật tối ưu và môi trường triển khai để đạt được hiệu quả cao nhất.

Đánh giá kích thước mô hình
Bước đầu tiên là ước tính lượng VRAM cần thiết cho mô hình mục tiêu. Một nguyên tắc chung là tinh chỉnh toàn phần cần khoảng 16 GB VRAM cho mỗi tỷ tham số. Điều này có nghĩa là một mô hình 7B có thể cần hơn 100 GB bộ nhớ GPU nếu không áp dụng tối ưu hóa. Tuy nhiên, với các phương pháp tiết kiệm tham số như LoRA và QLoRA, yêu cầu này có thể giảm đáng kể, xuống dưới 24 GB. Chẳng hạn, một mô hình LLaMA-2 7B có thể được tinh chỉnh trên một chiếc NVIDIA RTX 4090 (24 GB) nếu sử dụng QLoRA.
Ghép nối mô hình với GPU
Sau khi đánh giá kích thước công việc, bước tiếp theo là ghép nối nó với loại GPU phù hợp. Các GPU tiêu dùng như RTX 4000 Ada, RTX 6000 Ada và L40S rất phù hợp cho các phương pháp tinh chỉnh tiết kiệm tham số (như LoRA và QLoRA), đào tạo các mô hình nhỏ hơn (lên đến 7B tham số) và chạy các tác vụ suy luận hoặc thử nghiệm. Trong khi đó, các mô hình như NVIDIA H100 (80 GB) lại cần thiết cho các dự án học máy quy mô lớn, thực hiện đào tạo toàn bộ tham số hoặc học tăng cường từ phản hồi của con người (RLHF).
Ví dụ, bạn có thể bắt đầu với các GPU Droplet của DigitalOcean như NVIDIA L40S để thử nghiệm và tinh chỉnh hiệu quả. Khi khối lượng công việc tăng, bạn có thể mở rộng theo chiều ngang bằng cách thêm nhiều GPU Droplet kết nối qua mạng VPC, hoặc tích hợp với các nhà cung cấp GPU ngoài như MI300X/H100 thông qua mạng đám mây lai (hybrid cloud).
Tối ưu hóa quá trình đào tạo
Hiệu quả của việc tinh chỉnh không chỉ phụ thuộc vào phần cứng GPU, mà còn ở cách bạn thực hiện quá trình đào tạo. Các kỹ thuật như đào tạo hỗn hợp chính xác (mixed precision training – FP16 hoặc BF16) giúp giảm dung lượng bộ nhớ sử dụng nhưng vẫn giữ được độ chính xác. Kỹ thuật checkpointing gradient cho phép các mô hình lớn vừa vặn với dung lượng VRAM hạn chế bằng cách tính toán lại các kích hoạt trong quá trình lan truyền ngược, trong khi các điểm checkpoint đào tạo thông thường giúp bảo vệ tiến độ công việc khỏi sự cố hoặc bị gián đoạn.
Ví dụ, một mô hình 13B tham số thường cần nhiều GPU A100 để đào tạo, nhưng có thể được tinh chỉnh trên một GPU 24 GB duy nhất nếu kết hợp với QLoRA và checkpointing gradient. Trên các GPU Droplet của DigitalOcean, những điểm checkpoint này có thể được lưu trữ lâu dài trên Block Storage hoặc Spaces để đảm bảo tính sẵn sàng.
Đào tạo đa GPU
Đối với các mô hình trong khoảng 30B đến 70B tham số, việc sử dụng một GPU duy nhất là không khả thi. Lúc này, đào tạo phân tán là giải pháp cần thiết. Các framework như PyTorch Fully Sharded Data Parallel (FSDP) sẽ chia các tham số mô hình, gradient và trạng thái bộ tối ưu hóa ra nhiều GPU để cân bằng mức tiêu thụ bộ nhớ. Các kết nối băng thông cao như NVLink hay NVSwitch giúp giảm thiểu các nút thắt cổ chai trong quá trình giao tiếp. Chẳng hạn, tinh chỉnh một mô hình 70B thường yêu cầu tám GPU A100 80 GB được kết nối bằng NVLink. Về phía AMD, GPU Instinct MI300X sử dụng Infinity Fabric™ và Infinity Links, cung cấp kết nối băng thông cao tương đương.
DigitalOcean đơn giản hóa các quy trình làm việc đa nút và đa GPU bằng cách hỗ trợ MLOps và tích hợp với các framework như Hugging Face và DeepSpeed.
Cân nhắc chi phí
Lựa chọn GPU cũng gắn liền với yếu tố chi phí. Việc thuê GPU trên đám mây là một lựa chọn tuyệt vời cho các nhóm nghiên cứu đang thử nghiệm mô hình. Đối với các công ty khởi nghiệp và doanh nghiệp công nghệ số, chiến lược ưu tiên đám mây mang lại lợi thế về chi phí vận hành có thể dự đoán được, cùng khả năng mở rộng tài nguyên GPU linh hoạt dựa trên nhu cầu thực tế. Khi khối lượng công việc tăng lên hoặc trở nên thường xuyên hơn, các doanh nghiệp lớn hơn có thể cân nhắc đầu tư vào các máy chủ GPU bare-metal riêng biệt để tối ưu chi phí cho các tác vụ tinh chỉnh lặp lại.

Các phương pháp tối ưu khi tinh chỉnh với GPU
Ngoài các bước bắt buộc để tinh chỉnh thành công, một số phương pháp bổ sung dưới đây sẽ giúp bạn cải thiện hiệu suất, giảm chi phí và đảm bảo khả năng mở rộng mượt mà hơn.
Áp dụng các bộ tối ưu hóa tiết kiệm bộ nhớ
Các framework như DeepSpeed ZeRO hoặc AdamW giúp giảm gánh nặng từ trạng thái của bộ tối ưu hóa và cải thiện khả năng mở rộng trong các hệ thống đa GPU. Đối với các tác vụ tinh chỉnh LoRA nhỏ hơn, chúng không bắt buộc, nhưng lại cực kỳ hữu ích ở quy mô lớn.
Sử dụng đào tạo hỗn hợp chính xác (Mixed Precision Training)
Bạn nên bật FP16 hoặc BF16 bất cứ khi nào có thể để giảm dung lượng bộ nhớ và tăng tốc độ xử lý so với FP32. Mặc dù không bắt buộc đối với các GPU có dung lượng VRAM cực lớn, đây vẫn là một kỹ thuật được sử dụng rộng rãi để tối ưu hiệu suất. Ví dụ, việc sử dụng độ chính xác FP8 trên NVIDIA H100s với TensorRT-LLM cho mô hình Mixtral 8x7B giúp tăng thông lượng và giảm độ trễ đáng kể so với FP16.
Theo dõi hiệu suất GPU
Các công cụ như nvidia-smi hoặc PyTorch profiler sẽ giúp bạn phát hiện tình trạng sử dụng GPU dưới mức tối đa, thường do các nút thắt cổ chai trong quá trình tải dữ liệu. Đảm bảo GPU luôn được sử dụng hết công suất sẽ giúp bạn tránh lãng phí thời gian và chi phí đào tạo đắt đỏ.
Những thách thức khi tinh chỉnh với GPU
Yêu cầu VRAM cao
Tinh chỉnh toàn phần đòi hỏi khoảng 16 GB VRAM cho mỗi 1 tỷ tham số. Điều này có nghĩa là một mô hình 13B có thể cần hơn 200 GB VRAM. Ví dụ, để tinh chỉnh mô hình Falcon-13B ở định dạng FP16, bạn sẽ cần tới hơn 200 GB VRAM. Trên một chiếc GPU đơn lẻ như RTX 4090 (24 GB), quá trình này gần như là không thể.
Gánh nặng từ trạng thái của bộ tối ưu hóa
Các bộ tối ưu hóa như AdamW lưu trữ nhiều bản sao của các tham số mô hình (trọng số, gradient, động lượng, phương sai), khiến dung lượng bộ nhớ sử dụng tăng lên gấp ba lần. Đối với một mô hình 13B (với khoảng 26 GB trọng số ở định dạng FP16), trạng thái của bộ tối ưu hóa có thể đẩy nhu cầu bộ nhớ vượt quá 78 GB, buộc bạn phải dùng đến các thiết lập đa GPU hoặc các bộ tối ưu hóa ZeRO.
Khả năng cung cấp phần cứng
Các GPU cao cấp như A100 hoặc H100 hiện khá khan hiếm và có thể bị giới hạn ở một số khu vực đám mây nhất định. Điều này buộc các nhà phát triển ở các vùng khác phải phụ thuộc vào những GPU kém mạnh hơn, từ đó có thể giới hạn kích thước mô hình hoặc yêu cầu phải sử dụng cấu hình đa GPU.
Tổng chi phí sở hữu (TCO) Tinh chỉnh mô hình không chỉ tốn chi phí thuê GPU. Bạn còn phải tính đến chi phí lưu trữ, mạng và điện năng cho những tác vụ chạy trong thời gian dài. Ví dụ, việc chạy mô hình trong một tuần trên tám GPU A100 80GB có thể vượt quá ngân sách tùy thuộc vào nhà cung cấp đám mây, khiến việc thử nghiệm trở nên đắt đỏ nếu không được tối ưu cẩn thận. Bạn có thể kiểm soát chi phí bằng cách cân nhắc kích thước tài nguyên một cách cẩn thận, lên lịch công việc tự động vào giờ thấp điểm và sử dụng các phương pháp tinh chỉnh tiết kiệm tham số, vốn đòi hỏi sức mạnh tính toán ít hơn đáng kể.
Đẩy nhanh các dự án AI của bạn với DigitalOcean Gradient™ AI Droplets
Việc lựa chọn GPU đúng đắn sẽ giúp bạn khai phá sức mạnh của chúng cho các dự án AI và máy học. DigitalOcean GPU Droplets cung cấp khả năng truy cập theo yêu cầu vào các tài nguyên điện toán hiệu năng cao, giúp các nhà phát triển, công ty khởi nghiệp và những người đổi mới có thể đào tạo mô hình, xử lý các tập dữ liệu lớn và mở rộng các dự án AI mà không gặp phải sự phức tạp hay cần vốn đầu tư ban đầu.
Các tính năng nổi bật:
- Được hỗ trợ bởi GPU NVIDIA H100, H200, RTX 6000 Ada, L40S và AMD MI300X
- Tiết kiệm tới 75% so với các nhà cung cấp dịch vụ siêu quy mô cho cùng một GPU theo yêu cầu
- Cấu hình linh hoạt từ thiết lập một GPU đến 8 GPU
- Các gói phần mềm Python và Deep Learning được cài đặt sẵn
- Bao gồm đĩa khởi động cục bộ và đĩa tạm hiệu suất cao
- Đủ điều kiện theo HIPAA và tuân thủ SOC 2 với SLA cấp doanh nghiệp
Đọc thêm: On-Premise GPU vs Cloud GPU: Giải Pháp Tối Ưu Cho Dự Án AI?
Liên hệ CloudAZ ngay hôm nay để nhận tư vấn chuyên sâu về các giải pháp GPU từ DigitalOcean GPU Droplets giúp tối ưu hóa chi phí và hiệu suất cho dự án của bạn.









