Khi nhắc đến mối quan hệ giữa máy tính và ngôn ngữ, nhiều người thường nghĩ ngay đến lập trình — nơi các ngôn ngữ như Python, JavaScript, C++ hay Java được sử dụng để viết các chỉ thị, hướng dẫn hệ thống cần làm gì và phản hồi ra sao trước những lệnh cụ thể. Các ngôn ngữ lập trình này cung cấp cấu trúc cú pháp và tập từ vựng chặt chẽ, giúp con người giao tiếp hiệu quả với máy tính.
Tuy nhiên, với sự phát triển của trí tuệ nhân tạo, bức tranh đó đang dần thay đổi. Chúng ta đang bước vào một kỷ nguyên mới, nơi việc “trò chuyện” với máy tính trở nên tự nhiên và mang tính con người hơn rất nhiều. Người dùng có thể tương tác với hệ thống bằng cách đặt câu hỏi hoặc thực hiện truy vấn tìm kiếm giống như khi trao đổi với đồng nghiệp hay bạn bè, và nhận lại phản hồi dưới dạng hội thoại.
Đứng sau những khả năng này là hai công nghệ then chốt: Xử lý ngôn ngữ tự nhiên (NLP – Natural Language Processing) và Hiểu ngôn ngữ tự nhiên (NLU – Natural Language Understanding). Cả hai đều là những nhánh quan trọng của AI và machine learning, giúp máy móc hiểu ngôn ngữ tốt hơn và tương tác với con người theo cách thân thiện hơn, ít mang tính kỹ thuật hơn.
Trong bối cảnh so sánh NLP vs NLU, bài viết sẽ làm rõ những điểm tương đồng, khác biệt giữa hai công nghệ, các trường hợp ứng dụng phổ biến, cũng như những yếu tố cần cân nhắc khi triển khai chúng trong thực tế.
NLP là gì? (Natural Language Processing)

Xử lý ngôn ngữ tự nhiên (NLP) là một lĩnh vực con của trí tuệ nhân tạo, ứng dụng deep learning nhằm giúp máy tính xử lý, phân tích và tạo sinh ngôn ngữ của con người. NLP kết hợp các thuật toán machine learning với ngôn ngữ học tính toán để phân tích văn bản và lời nói, đồng thời liên tục cải thiện khả năng hiểu theo thời gian nhằm tạo ra các phản hồi ngày càng chính xác và tinh vi hơn.
Các trường hợp ứng dụng tiêu biểu của NLP bao gồm: phân loại văn bản, phân tích ngữ nghĩa, tạo sinh ngôn ngữ tự nhiên và dịch máy.
Việc triển khai NLP thường trải qua các bước chính như thu thập dữ liệu, tiền xử lý dữ liệu và huấn luyện mô hình. Trong đó, giai đoạn tiền xử lý đóng vai trò then chốt, sử dụng nhiều kỹ thuật như tách từ (tokenization), rút gọn từ (stemming), chuẩn hóa từ (lemmatization) và loại bỏ từ dừng (stop word removal) để đảm bảo dữ liệu đầu vào phù hợp và hiệu quả cho quá trình huấn luyện.
Một số công cụ NLP phổ biến hiện nay có thể kể đến như SpaCy, Hugging Face Transformers, Natural Language Toolkit (NLTK) và IBM Watson.
NLU là gì? (Natural Language Understanding)

Hiểu ngôn ngữ tự nhiên (NLU) là một nhánh chuyên sâu của NLP, tập trung vào việc giúp máy tính thực sự hiểu ngôn ngữ con người như cách nó được nói hoặc viết trong thực tế.
Khác với NLP ở phạm vi rộng, NLU tập trung mạnh vào khía cạnh diễn giải và trích xuất ý nghĩa. Thông qua các thuật toán phức tạp, NLU cho phép hệ thống nắm bắt sắc thái ngữ nghĩa, xác định ngữ cảnh, nhận diện ý định của người dùng và rút ra những insight có giá trị từ dữ liệu văn bản phi cấu trúc. Đây chính là nền tảng để xây dựng các hệ thống có khả năng tương tác với con người một cách tự nhiên, không còn phụ thuộc vào các câu lệnh cứng nhắc hay cấu trúc định sẵn.
Các công cụ tiêu biểu cho NLU bao gồm Rasa NLU và Snips. Bên cạnh đó, nhiều nền tảng NLP toàn diện (như các công cụ đã đề cập ở trên) cũng tích hợp sẵn khả năng hỗ trợ NLU, cho phép doanh nghiệp triển khai các giải pháp hội thoại và phân tích ngôn ngữ ở mức độ sâu hơn.
NLU hoạt động như thế nào?
Hiểu ngôn ngữ tự nhiên (NLU) vận hành dựa trên các thuật toán nhằm giúp máy móc diễn giải ngôn ngữ, suy luận ý nghĩa, xác định ngữ cảnh và rút ra các insight có giá trị. Để làm được điều này, NLU thu thập dữ liệu ngôn ngữ (đặc biệt là dữ liệu lời nói và văn bản), sau đó chuyển đổi chúng thành một ontology có cấu trúc — mô hình dữ liệu bao gồm các định nghĩa về ngữ nghĩa (semantics) và ngữ dụng (pragmatics).
Ontology này thể hiện các mối quan hệ và thuộc tính giữa các khái niệm, đồng thời tổ chức chúng theo từng miền ngữ cảnh (domain) cụ thể. Nhờ vậy, hệ thống có thể hiểu rằng cùng một từ như “diamond” có thể mang nhiều ý nghĩa khác nhau, chẳng hạn là một chất liệu trang sức, một thuật ngữ trong bóng chày, hoặc một chất trong bộ bài, tùy thuộc vào ngữ cảnh sử dụng.
Khi ontology đã được thiết lập, NLU bắt đầu quá trình nhận diện ý định (intent recognition) và nhận diện thực thể (entity recognition). Nhận diện ý định giúp hệ thống xác định mục tiêu và nhu cầu của người dùng, đồng thời phân tích sắc thái hoặc cảm xúc trong câu lệnh. Trong khi đó, nhận diện thực thể tập trung vào việc trích xuất các thực thể có tên riêng hoặc giá trị số trong câu hoặc tập dữ liệu, sau đó phân tích sâu hơn để bổ sung thông tin liên quan.
Để thực hiện các bước này, NLU trước hết sẽ phân tách ngôn ngữ thành các đơn vị nhỏ gọi là token. Mô hình NLU tiếp tục xử lý từng token nhằm xác định từ loại (part of speech) và vai trò của chúng trong câu. Quá trình này không chỉ dừng ở việc gán nhãn từ loại, mà còn tái phân tích để làm rõ các khả năng nghĩa khác nhau và cách mỗi từ liên kết với những từ còn lại trong toàn bộ ngữ cảnh.
Ví dụ, khi người dùng nhập truy vấn:
“attend a concert at the Seattle Symphony on August 22nd” vào một công cụ tìm kiếm có tích hợp NLU, hệ thống có thể phân tích như sau:
- Mục đích (intent): tìm vé hòa nhạc
- Nhu cầu: xem chỗ ngồi còn trống
- Địa điểm: Seattle Symphony
- Thời gian: ngày 22 tháng 8
Từ kết quả phân tích này, hệ thống xác định rõ nhu cầu, địa điểm, ý định và thời điểm của truy vấn. Công cụ tìm kiếm sau đó sẽ trả về các kết quả liên quan đến trang web của Seattle Symphony, đồng thời hiển thị thông tin về chỗ ngồi còn trống để người dùng có thể tiến hành mua vé cho các buổi hòa nhạc diễn ra vào ngày 22 tháng 8.
Tổng quan về NLP, NLU và NLG
Xử lý ngôn ngữ tự nhiên (NLP) và Hiểu ngôn ngữ tự nhiên (NLU) có mức độ giao thoa rất lớn. Cả hai đều là những lĩnh vực thuộc trí tuệ nhân tạo, tập trung vào việc xử lý và hiểu ngôn ngữ của con người. Hai công nghệ này cùng dựa trên các thuật toán machine learning và quá trình huấn luyện dữ liệu để đạt được mục tiêu cốt lõi của mình.
Điểm khác biệt giữa NLP vs NLU nằm ở vai trò cụ thể mà mỗi công nghệ đảm nhận trong quá trình giúp máy móc làm việc với ngôn ngữ.
- NLP tập trung vào việc biến ngôn ngữ trở nên “đọc được” đối với máy tính, xử lý dữ liệu đầu vào thông qua các bước như tách từ (tokenization), nhận diện thực thể, phân tích cú pháp và cấu trúc câu.
- NLU đi sâu hơn vào khả năng hiểu ngôn ngữ, hỗ trợ máy móc diễn giải ý nghĩa thông qua phân loại văn bản, phân tích cảm xúc, phân tích ngữ nghĩa và nhận diện ý định.
Dưới đây là so sánh trực quan giữa NLP và NLU:
| Tiêu chí | Natural Language Processing (NLP) | Natural Language Understanding (NLU) |
| Trọng tâm | Xử lý và phân tích dữ liệu ngôn ngữ ở mức nền tảng | Diễn giải đầu vào ngôn ngữ để đạt mức hiểu giống con người |
| Dữ liệu đầu vào | Văn bản hoặc lời nói | Văn bản hoặc lời nói |
| Kết quả đầu ra | Dữ liệu ngôn ngữ đã được cấu trúc | Dữ liệu phi cấu trúc đã được phân tích và hiểu |
| Kỹ thuật & xử lý | Sinh văn bản dựa trên luật, parsing, tokenization, gán nhãn từ loại | Hiểu ngôn ngữ nâng cao, xác định quan hệ giữa các từ, phân tích ý định và cảm xúc |
| Trường hợp ứng dụng | Phân tích văn bản, dịch ngôn ngữ, trợ lý thông minh | Phân tích cảm xúc, nhận dạng giọng nói |
Mặc dù có mục tiêu khác nhau, NLP và NLU luôn hoạt động song song và bổ trợ lẫn nhau. NLP đảm nhiệm việc xử lý và chuẩn hóa dữ liệu ngôn ngữ ban đầu, trong khi NLU tiếp nhận kết quả đó để phân tích sâu hơn về ý nghĩa và ngữ cảnh.
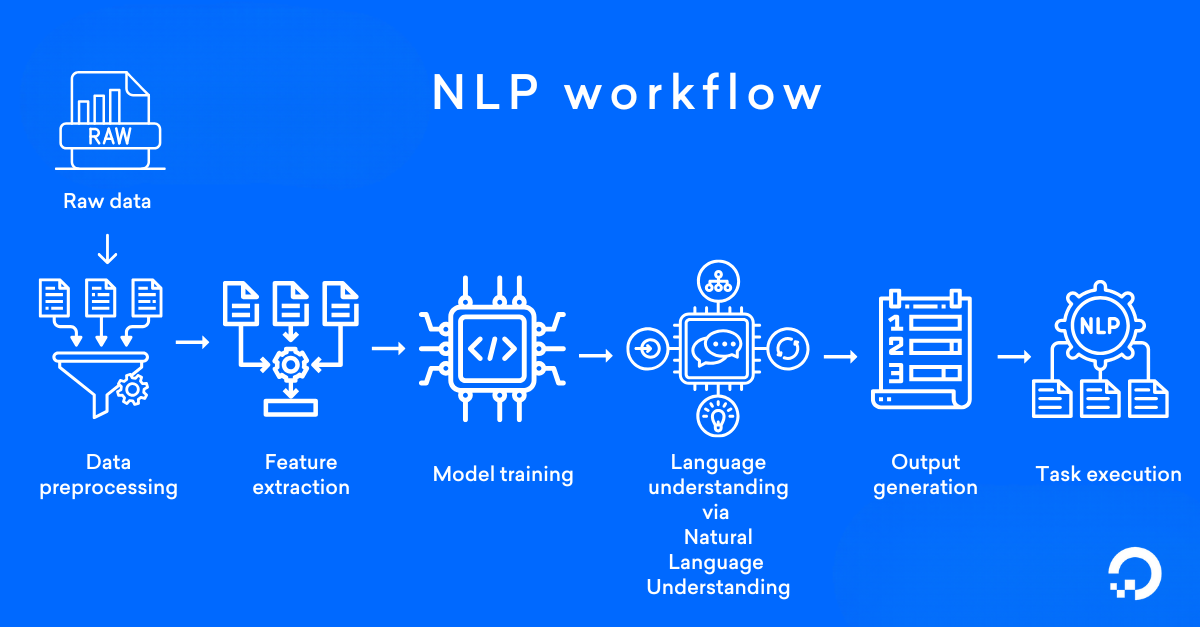
Sau khi toàn bộ quá trình xử lý và hiểu ngôn ngữ hoàn tất, mô hình machine learning sẽ tiếp tục sử dụng Tạo sinh ngôn ngữ tự nhiên (NLG – Natural Language Generation) để xây dựng phản hồi theo cách gần gũi, tự nhiên và mang tính hội thoại hơn với con người.
Để đạt được điều này, các mô hình NLG lần lượt thực hiện nhiều bước như phân tích nội dung, diễn giải và hiểu dữ liệu, tổ chức cấu trúc tài liệu, tổng hợp câu, xây dựng cấu trúc ngữ pháp và trình bày ngôn ngữ. Chuỗi xử lý này giúp hệ thống tạo ra phản hồi mạch lạc, dễ hiểu, đồng thời phù hợp với giọng điệu và phong cách giao tiếp mà hệ thống đã được thiết kế hướng tới, qua đó mang lại trải nghiệm tương tác tự nhiên và hiệu quả cho người dùng.
Các trường hợp ứng dụng của NLP và NLU
NLP và NLU thường được triển khai song song trong nhiều công cụ AI phục vụ năng suất và tự động hóa, với mục tiêu tiếp nhận ngôn ngữ tự nhiên của con người, đồng thời khai thác thông tin liên quan đến nhu cầu và ý định của người dùng. Trong khi NLP chủ yếu tập trung vào việc xác định những gì đã được nói hoặc viết, thì NLU đóng vai trò then chốt trong việc hiểu người dùng thực sự muốn nói gì. Sự kết hợp này giúp hệ thống có khả năng diễn giải ngôn ngữ con người một cách chính xác và tự nhiên hơn.
Dưới đây là một số trường hợp ứng dụng phổ biến nhất của hai công nghệ này:
Chatbot
Chatbot hiện là một trong những ứng dụng tiêu biểu nhất trong lĩnh vực chăm sóc khách hàng. Chúng cho phép người dùng tương tác với thương hiệu để nhận hỗ trợ hoặc hoàn thành các tác vụ cụ thể như đặt lịch họp, yêu cầu demo sản phẩm, tra cứu thông tin tài khoản hoặc truy xuất tài liệu.
Ở các thế hệ chatbot truyền thống, NLP được sử dụng để quét câu lệnh đầu vào, nhận diện từ khóa và đưa ra phản hồi đã được lập trình sẵn, thường dựa trên cây quyết định hoặc logic “If This Then That”. Cách tiếp cận này giúp tự động hóa các kịch bản đơn giản nhưng vẫn còn hạn chế về mức độ linh hoạt và hiểu ngữ cảnh.
Ngày nay, chatbot đã phát triển mạnh mẽ nhờ tích hợp NLU. Công nghệ này cho phép hệ thống nhận diện ý định chính xác hơn và mang lại trải nghiệm tương tác gần với con người hơn. Thay vì yêu cầu người dùng chọn chủ đề từ menu hay kho tri thức có sẵn, chatbot có thể trực tiếp tiếp nhận câu hỏi hoặc yêu cầu được diễn đạt tự nhiên. Mô hình NLU sẽ phân tích để hiểu người dùng đang hỏi gì, nhận diện cảm xúc hoặc sắc thái trong lời nói, từ đó phản hồi phù hợp với từng ngữ cảnh cụ thể.
Bên cạnh đó, NLU còn có khả năng hiểu tốt hơn các cách diễn đạt đời thường, tiếng lóng hoặc hội thoại không trang trọng — điều mà NLP thuần túy khó xử lý hiệu quả. Không chỉ dừng lại ở việc phản hồi tức thời, các hệ thống chatbot hiện đại còn có thể ghi nhớ lịch sử tương tác, học từ hành vi và sở thích của người dùng, và tận dụng những thông tin này để cá nhân hóa các phản hồi trong những lần tương tác tiếp theo.
Trợ lý giọng nói
Trợ lý giọng nói là một ví dụ điển hình khác cho việc NLP và NLU phối hợp chặt chẽ với nhau. Trong kịch bản này, NLP đảm nhiệm vai trò nhận diện và chuyển đổi lời nói thành dữ liệu ngôn ngữ, xác định chính xác những gì người dùng đã nói. Tiếp đó, NLU phân tích sâu hơn để giải mã giọng điệu, cảm xúc, ý định cũng như các yếu tố ngữ cảnh bổ sung. Toàn bộ quá trình này diễn ra chỉ trong vài giây, trước khi NLG tạo sinh và trả về phản hồi phù hợp dưới dạng ngôn ngữ tự nhiên.
Những thách thức và sai sót của NLP và NLU

Mặc dù các mô hình NLP và NLU đã có nhiều bước tiến đáng kể theo thời gian, việc hiểu ngôn ngữ con người vẫn là một bài toán phức tạp. Khả năng của các mô hình này vẫn chịu giới hạn bởi độ đa dạng và chất lượng của dữ liệu huấn luyện, cũng như mức độ phức tạp vốn có của ngôn ngữ tự nhiên. Một số thách thức chính trong các ứng dụng xử lý ngôn ngữ bao gồm:
Tính mơ hồ của ngôn ngữ con người
Ngay cả khi được huấn luyện với khối lượng dữ liệu lớn, NLP và NLU vẫn gặp khó khăn trong việc diễn giải chính xác ngôn ngữ con người. Nguyên nhân đến từ việc một từ hoặc một câu có thể mang nhiều nghĩa khác nhau, việc sử dụng thành ngữ, lối nói ẩn dụ, cũng như các yếu tố văn hóa và xã hội ảnh hưởng đến cách lựa chọn từ ngữ, ngữ pháp và cấu trúc câu.
Bên cạnh đó, ngôn ngữ luôn không ngừng phát triển, với sự xuất hiện liên tục của cách dùng từ mới, tiếng lóng và “algospeak”. Về mặt lý thuyết, những thay đổi này có thể được xử lý thông qua việc huấn luyện mô hình chuyên sâu và liên tục, tuy nhiên điều đó đòi hỏi nguồn dữ liệu huấn luyện rất lớn, đa dạng và bao phủ nhiều nhóm đối tượng khác nhau — một yêu cầu không phải lúc nào cũng dễ dàng đáp ứng trong thực tế.
Kết quả dương tính giả và sai lệch dữ liệu
Trong NLP và NLU, dương tính giả (false positives) là những trường hợp hệ thống phân loại hoặc nhận diện sai thông tin. Ví dụ, hệ thống có thể xác định từ “Apple” trong câu “Apple pie is my favorite dessert” là một thực thể liên quan đến công ty công nghệ, thay vì hiểu đúng đó là tên một loại trái cây.
Những sai lệch như vậy không chỉ dẫn đến dữ liệu phân tích thiếu chính xác, mà còn gây ra các vấn đề như xuất hiện từ ngoài vốn từ (out-of-vocabulary), khả năng khái quát hóa kém đối với một số chủ đề hoặc thuật ngữ, và làm lộ rõ các giới hạn của hệ thống.
Để cải thiện độ chính xác và độ tin cậy, các tổ chức có thể áp dụng nhiều phương pháp như mô hình xác suất (cho phép định lượng mức độ không chắc chắn), sử dụng điểm tin cậy (confidence scores), tinh chỉnh ngưỡng quyết định (threshold tuning) và các kỹ thuật học tổ hợp (ensemble learning). Những biện pháp này giúp hệ thống đưa ra quyết định cân bằng hơn, giảm thiểu sai sót trong quá trình xử lý và hiểu ngôn ngữ tự nhiên.
Xây dựng giải pháp với DigitalOcean Gradient Platform
DigitalOcean Gradient Platform giúp đơn giản hóa quá trình xây dựng và triển khai các AI agent mà không cần quản lý hạ tầng phức tạp. Nền tảng cho phép tạo các agent tùy chỉnh, được quản lý hoàn toàn, vận hành trên những mô hình ngôn ngữ lớn (LLM) hàng đầu thế giới như Anthropic, DeepSeek, Meta, Mistral và OpenAI. Từ chatbot tương tác trực tiếp với khách hàng đến các quy trình đa agent phức tạp, doanh nghiệp có thể tích hợp agentic AI vào ứng dụng chỉ trong vài giờ, với cơ chế tính phí minh bạch theo mức sử dụng và không phát sinh gánh nặng vận hành hạ tầng.
Các tính năng nổi bật:
- Suy luận serverless với các LLM hàng đầu, tích hợp API đơn giản và nhanh chóng
- Quy trình RAG (Retrieval-Augmented Generation) kết hợp knowledge base để truy xuất thông tin chính xác và được tinh chỉnh
- Khả năng function calling cho phép truy cập dữ liệu và thông tin theo thời gian thực
- Hỗ trợ multi-agent và định tuyến agent nhằm xử lý các tác vụ phức tạp
- Cơ chế guardrails giúp kiểm soát nội dung, phát hiện dữ liệu nhạy cảm và đảm bảo tuân thủ
- Đoạn mã chatbot có thể nhúng trực tiếp, giúp tích hợp dễ dàng vào website
- Tính năng quản lý phiên bản và rollback, hỗ trợ thử nghiệm an toàn và linh hoạt
Bắt đầu với DigitalOcean Gradient Platform để tiếp cận đầy đủ các công cụ cần thiết nhằm xây dựng, vận hành và quản lý những giải pháp AI thế hệ mới, sẵn sàng mở rộng và tạo ra đột phá trong tương lai.
Tìm hiểu thêm:
TOP 8 Dịch Vụ Quản Lý AI Tốt Nhất Năm 2026
TOP 10 Trợ lý AI mạnh mẽ thay thế Claude năm 2026
Liên hệ ngay với CloudAZ để được tư vấn 1-1 về các giải pháp phù hợp với nhu cầu phát triển của doanh nghiệp bạn!









