Prefix Catching là gì, trước sự bùng nổ của trí tuệ nhân tạo tạo sinh (Generative AI), nhu cầu triển khai các mô hình ngôn ngữ lớn (LLM) trong doanh nghiệp đang tăng trưởng mạnh mẽ. Tuy nhiên, khi mở rộng quy mô vận hành, nhiều tổ chức nhận ra rằng một phần đáng kể ngân sách hạ tầng AI đang bị tiêu tốn cho những phép tính lặp lại không cần thiết.
Nguyên nhân chính đến từ việc hệ thống liên tục xử lý lại các phần tiền tố (Prompt Prefix) giống nhau trong mỗi yêu cầu suy luận. Đây chính là bài toán mà Prefix Caching được tạo ra để giải quyết.
Tài liệu tham khảo:The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
Prefix Caching Là Gì?
Prefix Caching là kỹ thuật lưu trữ và tái sử dụng KV Cache (Key-Value Cache) của những phần tiền tố đầu vào đã được mô hình xử lý trước đó.
Thay vì phải tính toán lại toàn bộ System Prompt, hướng dẫn hệ thống hoặc ngữ cảnh dùng chung cho mỗi request mới, hệ thống có thể tận dụng kết quả đã lưu trong bộ nhớ đệm. Điều này giúp giảm đáng kể lượng phép tính cần thực hiện, rút ngắn thời gian phản hồi và tối ưu chi phí vận hành AI.
Nói một cách đơn giản, Prefix Caching cho phép mô hình “ghi nhớ” phần nội dung đã xử lý thay vì liên tục tính toán lại từ đầu.
Cơ Chế Hoạt Động Của Prefix Caching Ở Tầng Engine (vLLM)
Để giải quyết tận gốc vấn đề, công nghệ Prefix Caching phối hợp nhiều cơ chế thông minh bên trong phần mềm mã nguồn mở vLLM
Lưu trữ KV dựa trên khối (Block-Based KV Storage)
Thay vì lưu trữ các tensor Key và Value theo từng token (gây hỗn loạn bộ nhớ), vLLM chia chúng thành các khối cố định (mặc định là 16 tokens). Kỹ thuật này gọi là PagedAttention. Khi một System Prompt 2.000 token được nạp vào, nó sẽ chiếm 125 vị trí khối trong bộ nhớ GPU. Bất kỳ request nào sau đó có chung phần tiền tố này sẽ chỉ cần “trỏ” đến các khối sẵn có thay vì tính toán lại từ đầu.
Băm tiền tố và Tra cứu bộ đệm (Prefix Hashing & Cache Lookup)
Làm sao hệ thống biết được hai request có chung tiền tố? vLLM thực hiện băm (hash) các chuỗi tiền tố theo từng khối. Chuỗi hash này cũng phụ thuộc vào các yếu tố như ID của LoRA adapter hoặc dữ liệu đa phương thức. Khi có request mới, hệ thống chỉ cần đối chiếu chuỗi hash này với một bảng tra cứu (Lookup table) để tìm phần tiền tố dài nhất đã được lưu trong bộ nhớ đệm.
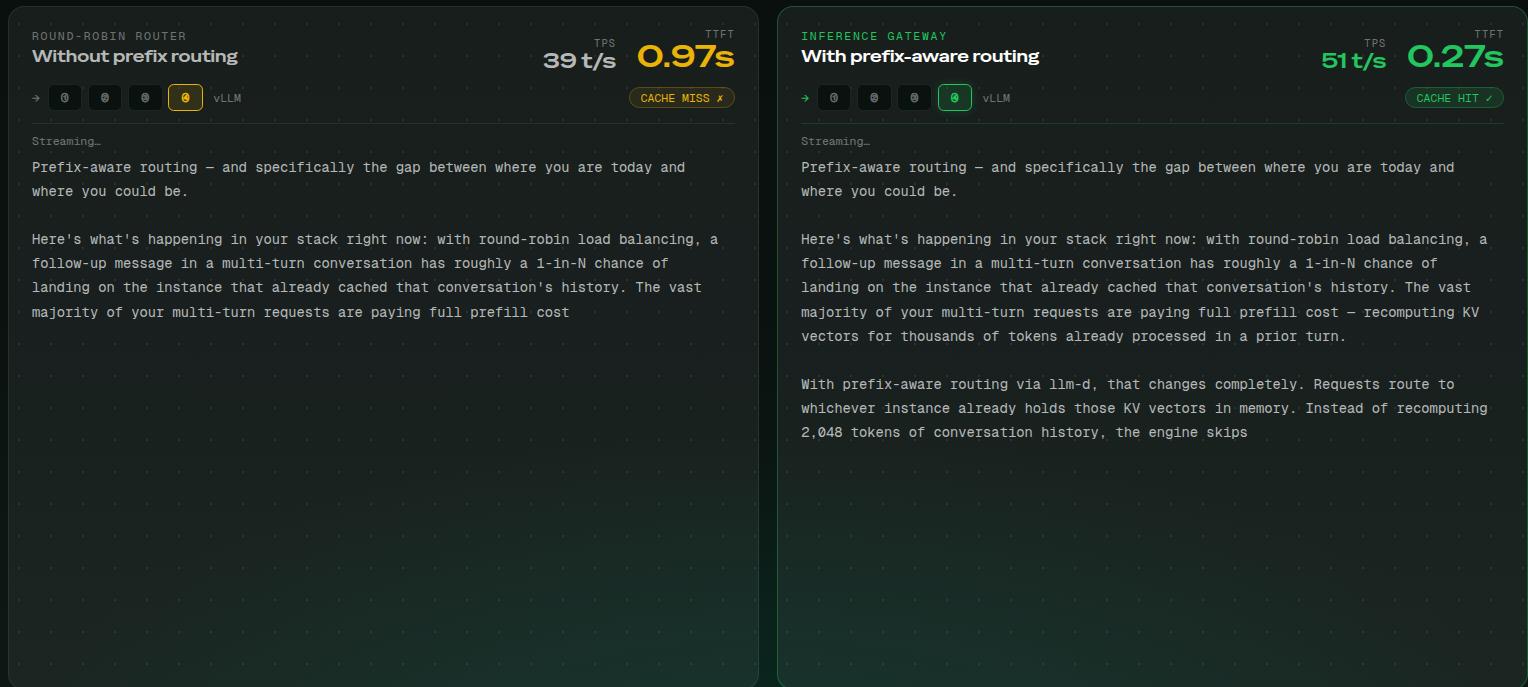
Tiết Kiệm FLOPs Nhờ Biến Cache Miss Thành Cache Hit
- Cache Miss (Trượt bộ đệm): Hệ thống phải chạy prefill toàn bộ đầu vào với chi phí tính toán đắt đỏ.
- Cache Hit (Trúng bộ đệm): Hệ thống bỏ qua hầu hết công việc. Trạng thái KV của tiền tố đã có sẵn trên GPU, mô hình chỉ cần tính toán nốt phần tin nhắn mới của người dùng. Kết quả là thời gian phản hồi từ đầu tiên (Time to First Token – TTFT) được giảm xuống gần như bằng 0.
Nâng Cấp Lên Quy Mô Lớn Với Prefix-Aware Routing (Định tuyến nhận biết tiền tố)
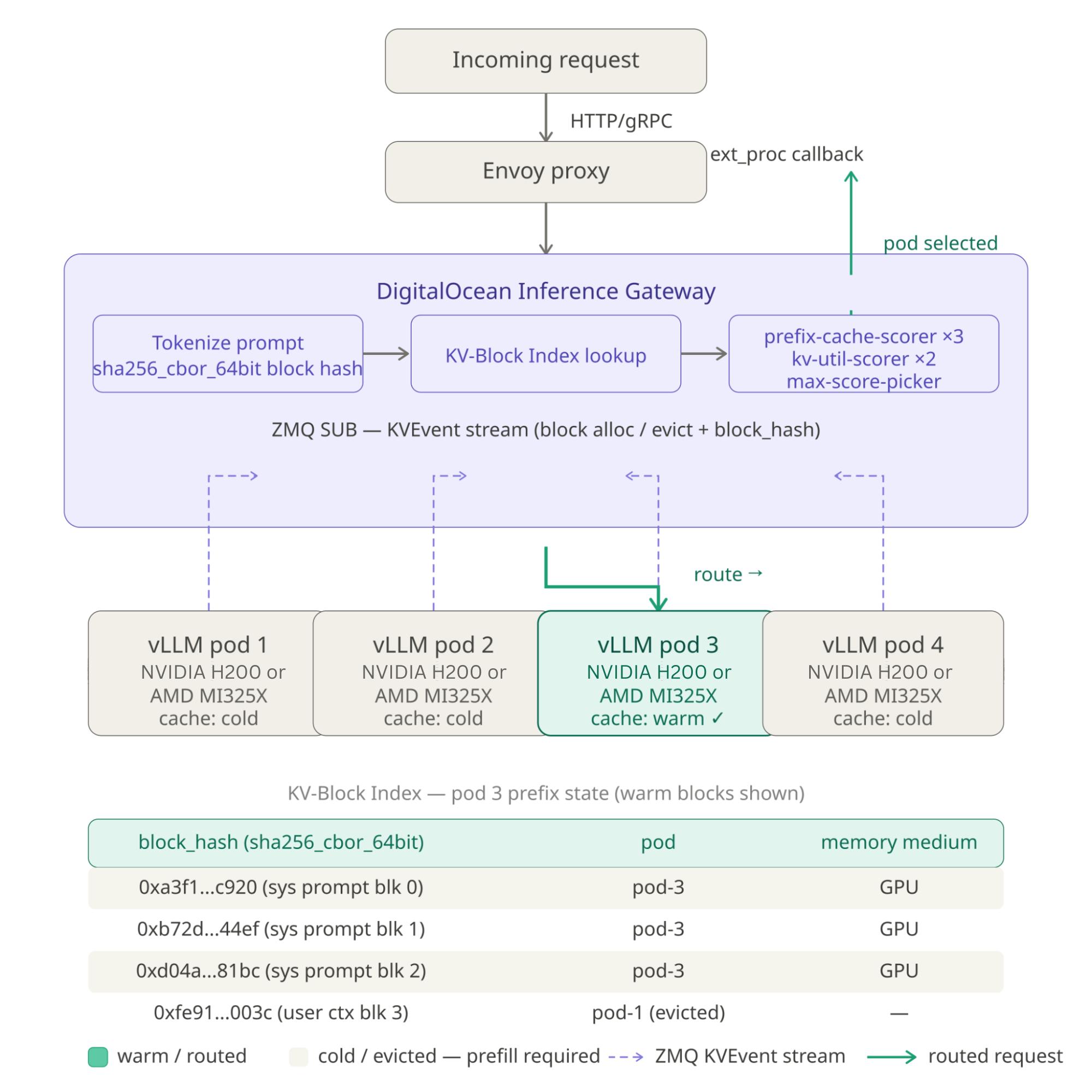
Một thực thể GPU đơn lẻ chỉ có thể lưu những gì bản thân nó từng xử lý. Nhưng trong một hệ thống lớn gồm nhiều cụm GPU (Cluster), làm sao để request của người dùng luôn tìm đến đúng GPU đang lưu sẳn bộ đệm của tiền tố đó?
Giải pháp chính là Prefix-Aware Routing (Định tuyến nhận biết tiền tố) thông qua một cổng kết nối trung gian (Inference Gateway).
- Các GPU chạy vLLM sẽ liên tục phát đi sự kiện bộ nhớ cache (khối nào được lưu, khối nào bị xóa) qua các kênh truyền thông báo tốc độ cao (như ZeroMQ).
- Bộ định tuyến (Router) sẽ thu thập dữ liệu này để tự xây dựng một “cây tiền tố toàn cầu” (Global Prefix Tree).
- Khi có request mới, Router không chỉ phân phối tải theo cách cân bằng ngẫu nhiên thông thường (Round-robin), mà nó sẽ ưu tiên chuyển request đến GPU nào đang có sẵn KV Cache cho tiền tố của request đó.
Sự kết hợp giữa xử lý tầng Engine (vLLM) và tầng Hạ tầng (Inference Gateway) giúp tối ưu hóa hiệu suất thiết bị một cách triệt để.
Tối Ưu Hóa Chi Phí AI Cho Doanh Nghiệp Bằng Prefix Catching
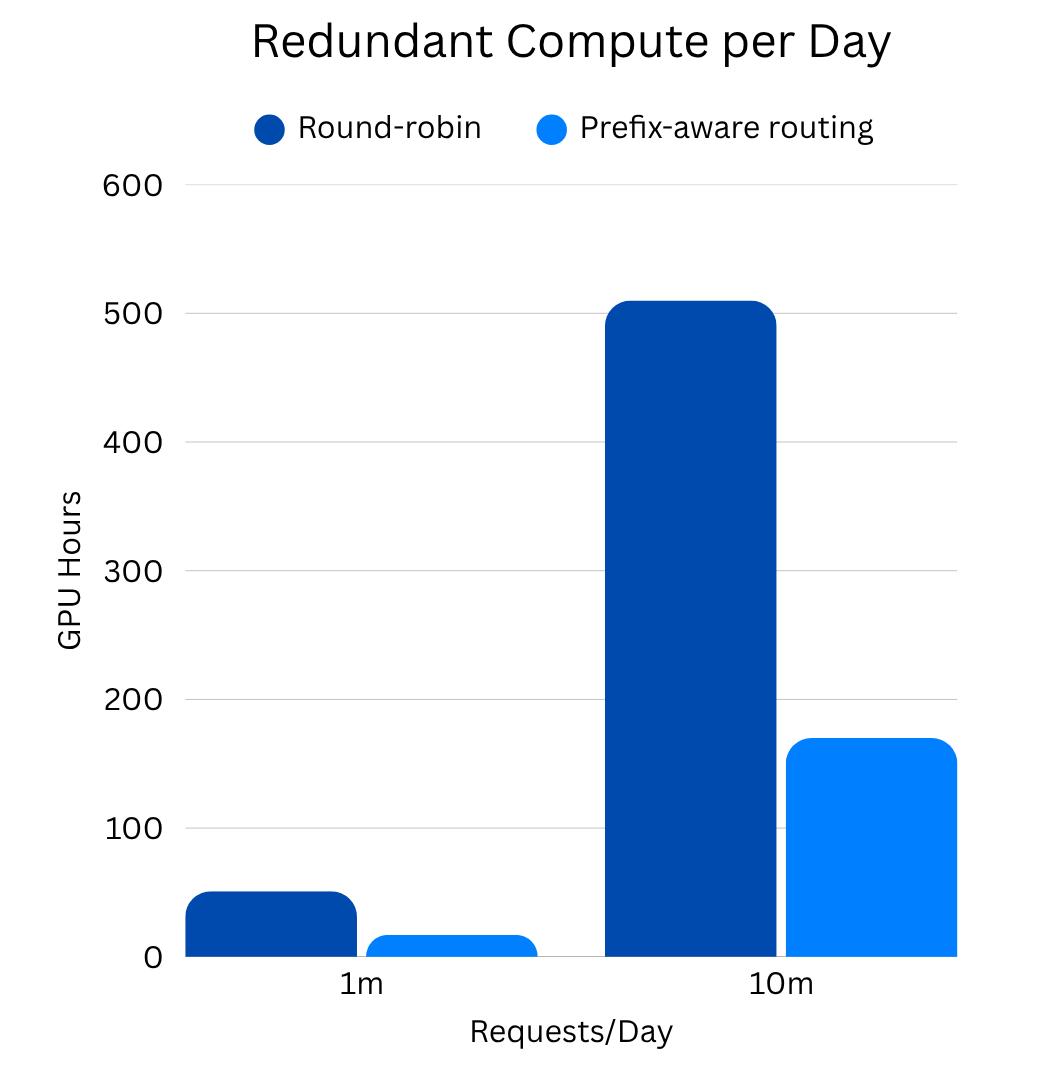
Nếu doanh nghiệp của bạn đang tự vận hành các ứng dụng AI như Trợ lý lập trình (Coding Assistant), Công cụ hỏi đáp tài liệu chuyên sâu (Document Q&A), hoặc Trợ lý ảo AI Agents… Prefix Caching chính là chìa khóa để tồn tại trong cuộc đua tối ưu chi phí.
Hiện nay, các nhà cung cấp hạ tầng đám mây lớn, điển hình như DigitalOcean, đã tích hợp sẵn các công nghệ này vào nền tảng Serverless Inference của họ. Khách hàng không cần phải tự cấu hình các thuật toán phức tạp, hệ thống sẽ tự động định tuyến thông minh, áp dụng Prefix Caching trên các dòng GPU cao cấp như NVIDIA Hopper hay AMD Instinct™ MI325X, mang lại mức giá sập sàn tính theo số token được lưu trong bộ đệm (Cached Token Pricing).
Tham khảo thêm: https://cloudaz.io/bi-quyet-chon-cloud-toi-uu-vi-sao-digitalocean-la-top-1/
Lời Kết
Prefix Caching là một trong những công nghệ quan trọng nhất giúp giảm chi phí suy luận LLM hiện nay. Bằng cách tái sử dụng KV Cache của các tiền tố đã xử lý, hệ thống có thể loại bỏ phần lớn “thuế prefill”, tăng tốc độ phản hồi và tối ưu hiệu suất GPU.
Khi kết hợp với Prefix-Aware Routing, doanh nghiệp có thể mở rộng hạ tầng AI hiệu quả hơn, giảm chi phí vận hành và tận dụng tối đa sức mạnh của các mô hình ngôn ngữ lớn.
Nếu đang triển khai chatbot AI, AI Agent, trợ lý lập trình hoặc hệ thống RAG, Prefix Caching nên được xem là một trong những ưu tiên hàng đầu để tối ưu chi phí và hiệu năng.









