Sự cố Cloudflare và bài học dành cho doanh nghiệp
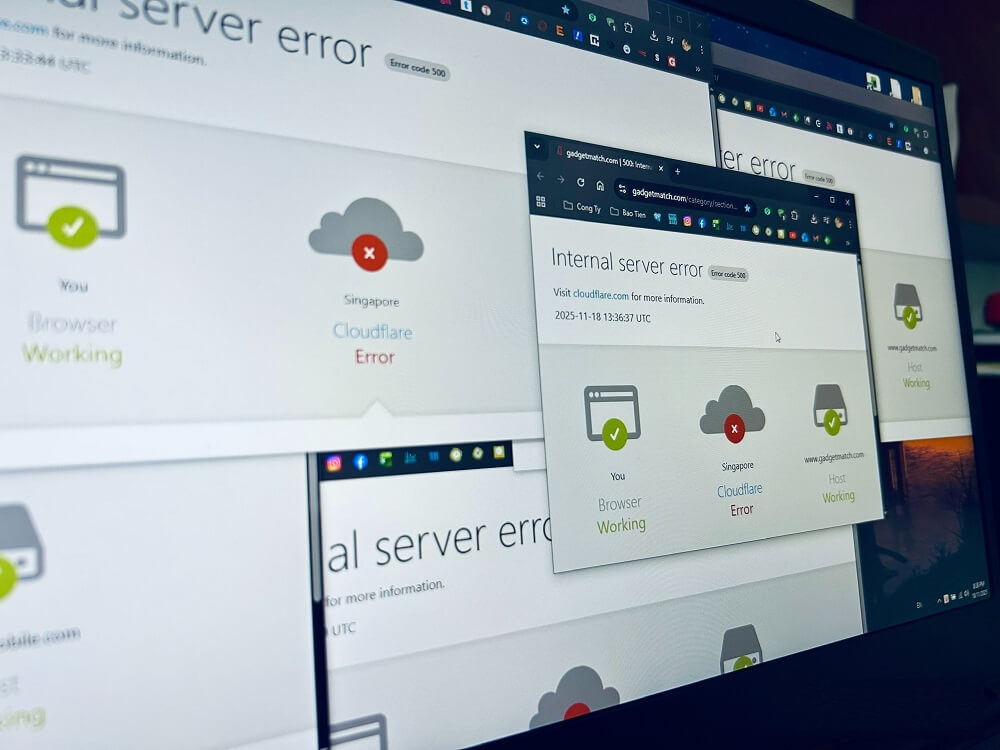
Sự cố “sập” toàn cầu của Cloudflare vừa qua đã tạo ra một cú sốc không hề nhỏ khi hàng loạt dịch vụ bất ngờ ngưng hoạt động chỉ trong vài phút. Điều đáng nói hơn cả là backend của nhiều ứng dụng vẫn chạy bình thường, nhưng người dùng vẫn không thể truy cập do nút thắt nằm ở chính tầng edge.
Sự cố này không chỉ là một vấn đề kỹ thuật tạm thời; nó phản ánh một rủi ro lớn mà các doanh nghiệp hiện đại cần nhìn nhận nghiêm túc: sự phụ thuộc quá mức vào một nền tảng duy nhất trong kiến trúc hạ tầng tố. Khi một dịch vụ quan trọng như Cloudflare hay AWS gặp vấn đề, toàn bộ mô hình vận hành có thể kéo sập theo chỉ vì không có cơ chế đa lớp hoặc phương án dự phòng.
Vì sao sự cố Cloudflare lại tác động mạnh và lan rộng?
Cloudflare vận hành trên mô hình edge-first, tức mọi yêu cầu đều phải đi qua tầng edge network trước khi đến backend. Cách làm này giúp tối ưu tốc độ, giảm tải cho server gốc và tăng cường bảo mật. Tuy nhiên, khi chính tầng edge gặp sự cố, toàn bộ traffic lập tức bị gián đoạn – giống như bạn có một hệ thống nội bộ ổn định nhưng chiếc cửa duy nhất để bước vào lại bị khóa.
Edge network – Lợi thế lớn nhưng cũng là điểm yếu
Cloudflare mạnh vì:
- Phân phối nội dung từ vị trí gần người dùng nhất
- Ngăn chặn tấn công DDos hiệu quả
- Tối ưu đường truyền và thời gian phản hồi
Nhưng khi edge gặp lỗi định tuyến, lỗi cấu hình, quá tải hoặc trục trặc hệ thống, hệ quả lập tức lan rộng. Vì vậy, hầu hết traffic đều đi qua Cloudflare, một lỗi nhỏ cũng đủ gây ảnh hưởng toàn cầu – điều mà mô hình cloud truyền thống thường không gặp phải.
Hiệu ứng Domino do mức độ phổ biến
Khoảng 20% website hoạt động dựa trên hạ của Cloudflare. Điều này đồng nghĩa: khi Cloudflare gặp downtime, tác động không chỉ giới hạn trong phạm vi một nhà cung cấp dịch vụ mà lan truyền như một hiệu ứng domino tới hàng triệu người dùng internet cùng thời điểm. Hệ quả tức thời là hàng triệu trang web phụ thuộc vào Cloudflare sẽ bị ảnh hưởng nghiêm trọng, bao gồm các dịch vụ lớn như Canva và ChatGPT (OpenAI).
Người dùng Canva bị gián đoạn quy trình làm việc vì không thể tải tài nguyên thiết kế, dẫn đến thiệt hại thương hiệu và mất dữ liệu tiềm năng đối với những người dùng đang làm việc trực tuyến.
Trong khi đó, người dùng ChatGPT bị ngắt kết nối, không thể tương tác với AI, và các ứng dụng tích hợp API của OpenAI cũng ngừng hoạt động hoàn toàn.
Sự phụ thuộc vào một vendor
Điều doanh nghiệp cần nhìn nhận rõ: sự cố của bất kỳ nền tảng nào cũng có thể xảy ra. Không có dịch vụ nào cam kết vận hành mãi mãi không lỗi. Vấn đề thật sự nằm ở chỗ nhiều doanh nghiệp đặt toàn bộ lớp truy cập của mình vào một nền tảng duy nhất.
Single vendor = Single point of failure
Khi toàn bộ traffic đi qua một lớp edge duy nhất, doanh nghiệp đối mặt với các rủi ro như:
- Không có đường dự phòng, dẫn đến downtime toàn hệ thống.
- Không khả năng bypass để đưa traffic trực tiếp vào backend.
- Không phân tách tải khiến mọi thành phần phụ thuộc lẫn nhau.
Điều này giải thích vì sao nhiều doanh nghiệp dù backend vẫn chạy bình thường nhưng frontend vẫn sập hoàn toàn.
Lỗ hổng trong tư duy triển khai hệ thống
Một trong những vấn đề cốt lõi mà sự cố Cloudflare bộc lộ không nằm ở chính nền tảng edge mà nằm ở cách nhiều doanh nghiệp đang tiếp cận việc xây dựng hạ tầng của họ. Rất nhiều tổ chức, đặc biệt là các doanh nghiệp vừa và nhỏ (SMEs), thường ưu tiên những lựa chọn “nhanh – gọn – tiết kiệm” và tập trung vào việc triển khai các giải pháp đáp ứng được nhu cầu trước mắt mà chưa thực sự xem xét đến khả năng chịu lỗi (fault tolerance) của toàn bộ hệ thống.
Trong thực tế, không ít doanh nghiệp vẫn duy trì tư duy:
- Đơn giản hóa hạ tầng quá mức dẫn đến việc nhiều thành phần quan trọng bị gom lại vào một lớp duy nhất thay vì tách biệt theo từng chức năng.
- Tối ưu chi phí trong ngắn hạn khiến họ bỏ qua những dịch vụ hoặc cơ chế dự phòng có thể đảm bảo tính ổn định lâu dài.
- Dựa toàn bộ vận hành vào một vendor duy nhất, từ CDN, DNS, bảo mật cho đến routing, tạo ra một điểm lỗi đơn (single point of failure) mà họ thậm chí không nhận ra.
Chính cách triển khai này khiến hệ thống trở nên mong manh hơn rất nhiều, chỉ một trục trặc nhỏ ở tầng edge đã đủ kéo toàn bộ dịch vụ vào trạng thái tê liệt, dù backend vẫn hoạt động hoàn toàn bình thường.
Nói cách khác, chi phí tiết kiệm được trong hiện tại không thể bù đắp cho rủi ro vận hành mà một sự cố bất ngờ có thể xảy ra, đặc biệt là khi hệ thống không được thiết kế với các lớp bảo vệ và dự phòng cần thiết.
Doanh nghiệp cần rút ra điều gì từ sự cố này?
Sự cố Cloudflare sập là một lời cảnh tỉnh đáng giá đối với nhiều doanh nghiệp, đặc biệt trong bối cảnh phần lớn hệ thống đang được vận hành theo tiêu chí “nhanh – gọn – rẻ”, nhưng lại thiếu những chuẩn bị cần thiết cho các tình huống gián đoạn dịch vụ. Khi thị trường ngày càng cạnh tranh hơn và hành vi người dùng trở nên khó đoán hơn, việc đánh giá lại khả năng chịu lỗi của hệ thống không còn là việc “nên làm” mà đã trở thành yêu cầu bắt buộc nếu doanh nghiệp muốn giữ uy tín và đảm bảo tăng trưởng bền vững.
Hậu quả khôn lường của Downtime
Downtime không cần kéo dài quá lâu để gây ra hậu quả, đôi khi chỉ cần vài phút mất kết nối cũng đủ tạo ra những tác động đáng kể:
- Gián đoạn quy trình đặt hàng hoặc thanh toán
- Mất phiên đăng nhập và giảm tỷ lệ chuyển đổi
- Người dùng rời bỏ trang truy cập thất bại
- Giảm sút niềm tin vào chất lượng dịch vụ
Giải pháp hạ tầng phân tán với Google Cloud
Những tác động này cho thấy doanh nghiệp cần chủ động xây dựng kiến trúc có khả năng phân tán rủi ro và phục hồi nhanh. Tận dụng các nền tảng cloud có khả năng multi-region, global load balancing và geo-redundancy như Google Cloud sẽ giúp doanh nghiệp hạn chế phụ thuộc vào một điểm lỗi duy nhất. Với các dịch vụ như Cloud Load Balancing, Cloud CDN, Cloud DNS, Cloud Run hoặc GKE multi-region, Google Cloud cho phép hệ thống tiếp tục hoạt động kể cả khi một lớp hạ tầng bên ngoài – như CDN, DNS hoặc edge network – gặp trục trặc.
Việc kết hợp kiến trúc resilient với năng lực phân tán của Google Cloud giúp doanh nghiệp:
- Duy trì dịch vụ ngay cả khi một thành phần hạ tầng gặp lỗi,
- Giảm thiểu tác động dây chuyền khi xảy ra sự cố,
- Nâng cao SLA và tính liên tục dịch vụ,
- Xây dựng trải nghiệm ổn định hơn cho khách hàng trong mọi điều kiện.
Về bản chất, đầu tư vào resilience và tận dụng kiến trúc phân tán của Google Cloud là một chiến lược dài hạn, giúp doanh nghiệp không chỉ giảm thiểu thiệt hại khi có sự cố mà còn tạo ra nền tảng bền vững để mở rộng và duy trì niềm tin từ người dùng.
Kết luận
Sự cố Cloudflare không phải là điều bất thường trong bối cảnh Internet vận hành với hàng trăm lớp hạ tầng phức tạp và luôn tiềm ẩn nguy cơ gián đoạn. Tuy nhiên, điều khiến sự cố này trở nên đáng chú ý chính là cách nó phơi bày sự phụ thuộc của nhiều doanh nghiệp vào một tầng kỹ thuật duy nhất và mức độ tổn thương khi thiếu các cơ chế dự phòng. Một kiến trúc resilient, đa lớp và có khả năng chịu lỗi sẽ giúp doanh nghiệp đứng vững ngay cả trong những tình huống bất thường, bảo vệ trải nghiệm người dùng và duy trì tính liên tục của dịch vụ.
Trong quá trình xây dựng năng lực này, nhiều doanh nghiệp tìm đến các đơn vị tư vấn am hiểu hạ tầng đám mây và có kinh nghiệm triển khai các mô hình vận hành ổn định hơn. Các đội ngũ như CloudAZ, vốn đã quen với việc thiết kế hệ thống multi-region, tối ưu khả năng phục hồi và đảm bảo tính liên tục dịch vụ trên Google Cloud, thường đóng vai trò hỗ trợ để doanh nghiệp nhận diện rủi ro, tái cấu trúc những điểm yếu và củng cố khả năng chịu lỗi một cách thực tế, vừa sức.
Sự cố Cloudflare có thể chỉ diễn ra trong thời gian ngắn nhưng bài học về resilience thì mang giá trị lâu dài. Việc chuẩn bị sớm, hiểu rõ hạ tầng của mình và chủ động xây dựng các lớp bảo vệ hợp lý sẽ là nền tảng giúp doanh nghiệp vận hành bền vững và tự tin hơn trước những biến động khó lường trong tương lai.









